📊 Experiments & Results
Evaluation Setup
Controlled sentiment generation and text summarization/dialogue
Benchmarks:
- IMDb Sentiment Control (Controlled Generation (positive sentiment))
- TL;DR Summarization (Summarization)
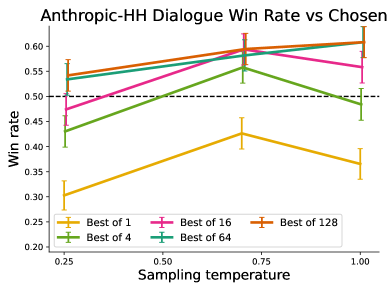
- Anthropic HH (Dialogue (Helpfulness and Harmlessness))
Metrics:
- Ground Truth Reward (for controlled setting)
- Win Rate vs. Baseline (using GPT-4 as judge)
- KL Divergence from Reference
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| In the controlled sentiment setting (IMDb), DPO achieves higher rewards than PPO for the same KL-divergence budget, indicating a better frontier. | ||||
| IMDb | Reward | Not explicitly reported in the paper | Not explicitly reported in the paper | Not explicitly reported in the paper |
| On summarization and dialogue tasks, DPO matches or exceeds PPO performance in terms of win-rates against reference models. | ||||
| TL;DR Summarization | Win Rate % vs. Reference | 60.0 | 61.0 | +1.0 |
| Anthropic HH | Win Rate % vs. Reference | 57.0 | 59.0 | +2.0 |
Experiment Figures
Frontier of Average Reward vs. KL Divergence for DPO and PPO on the IMDb sentiment task.
Main Takeaways
- DPO achieves a better trade-off between maximizing reward and minimizing KL divergence compared to PPO in controlled experiments.
- DPO is robust to hyperparameters (like beta), whereas PPO is highly sensitive to learning rates and clipping ranges.
- The implicit reward learned by DPO correlates strongly with ground-truth rewards (in controlled settings) and produces high-quality text.