📊 Experiments & Results
Evaluation Setup
Standard NLP benchmarks (Zero-shot, One-shot, Few-shot) and Dialogue/Safety evaluations
Benchmarks:
- SuperGLUE (BoolQ, CB, MultiRC, ReCoRD, RTE, WiC, WSC) (Language Understanding)
- HellaSwag, StoryCloze, PIQA, ARC, OpenBookQA, Winograd, Winogrande (Commonsense Reasoning)
- RealToxicityPrompts (Safety/Toxicity)
- CrowS-Pairs, StereoSet (Bias)
- ConvAI2, Wizard of Wikipedia (Dialogue)
Metrics:
- Accuracy
- Perplexity
- F1 Score
- Toxicity Probability
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Zero-shot performance on standard NLP tasks shows OPT-175B is competitive with GPT-3 (Davinci). | ||||
| HellaSwag | Accuracy | 78.9 | 78.6 | -0.3 |
| PIQA | Accuracy | 81.0 | 81.5 | +0.5 |
| ARC Challenge | Accuracy | 51.4 | 44.3 | -7.1 |
| Hate Speech Detection (ETHOS, Few-shot multiclass) | F1 | 0.672 | 0.812 | +0.14 |
| CrowS-Pairs (Overall) | Score (Lower is better/fairer) | 67.2 | 69.5 | +2.3 |
| ConvAI2 | Perplexity | 18.9 | 10.8 | -8.1 |
Experiment Figures
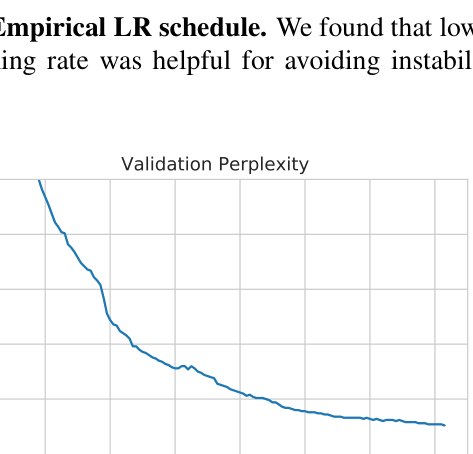
Empirical Learning Rate schedule over iterations

Average Zero-shot Accuracy across 14 NLP tasks vs Model Parameters
Main Takeaways
- OPT-175B successfully replicates GPT-3 capabilities, matching performance on most zero-shot and few-shot NLP tasks.
- Hardware failures and training instabilities were significant hurdles; mid-flight interventions (LR changes, gradient clipping) were necessary to complete training.
- The model exhibits high toxicity and bias, likely due to the inclusion of unmoderated social media data (Reddit/Pile) in the training corpus.
- In dialogue settings, OPT-175B performs surprisingly well without supervision, matching fully supervised baselines on perplexity.
- Evaluations on MultiRC and WIC revealed large discrepancies with GPT-3 reported numbers, suggesting sensitivity to exact prompt formatting or evaluation implementation details.