📝 Paper Summary
Reasoning Models
Reinforcement Learning from Verifiable Rewards (RLVR)
Chain-of-Thought Reasoning
Magistral demonstrates that large language models can significantly improve reasoning capabilities through pure reinforcement learning on verifiable rewards without distillation from stronger models, using a scalable asynchronous infrastructure.
Core Problem
Enhancing LLM reasoning usually relies on distilling traces from stronger models (like o1), and standard RL approaches struggle with stability, language mixing, and compute efficiency at scale.
Why it matters:
- Reliance on distillation limits models to the capabilities of the teacher, preventing true frontier exploration.
- Existing RL methods often degrade multilingual abilities or cause code-switching when optimizing for math/code rewards.
- Inefficient RL infrastructure creates bottlenecks, preventing the large-scale exploration needed for 'aha' moments in reasoning.
Concrete Example:
In preliminary experiments without language constraints, a model trained on math problems frequently output chains of thought mixing English, Chinese, and Russian. Magistral fixes this via a language consistency reward.
Key Novelty
Ground-up RLVR without Distillation
- Trains reasoning models (Small and Medium) using Group Relative Policy Optimization (GRPO) directly on verifiable rewards (math/code) without cloning traces from superior models.
- Introduces a 'language consistency' reward that forces the chain-of-thought and answer to match the user's prompt language, solving the code-switching problem common in reasoning RL.
- Uses a highly asynchronous infrastructure where generators never wait for trainers, prioritizing throughput and on-policy generation over perfect synchronization.
Architecture
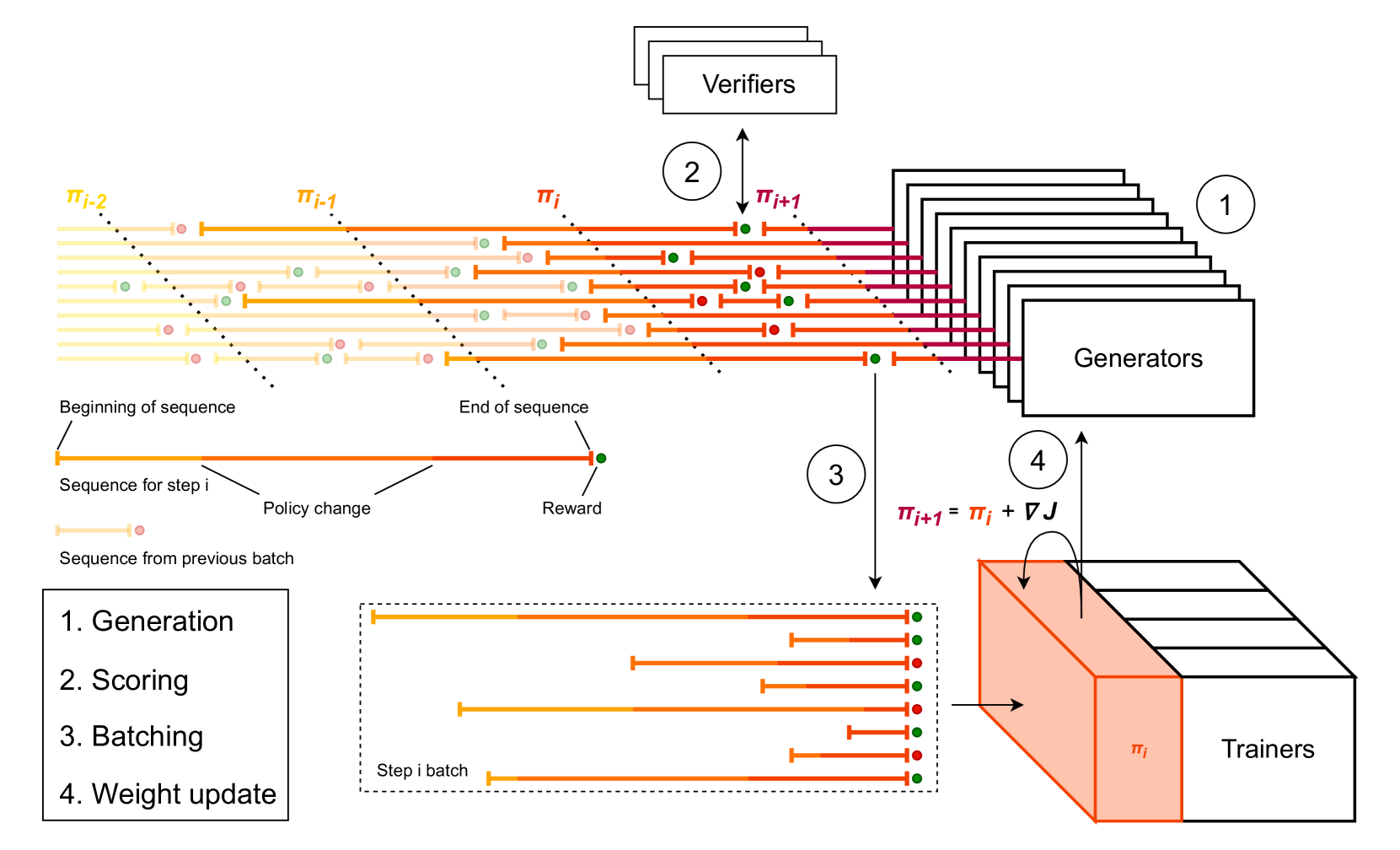
The asynchronous distributed RL training infrastructure.
Evaluation Highlights
- +50% improvement on AIME-24 (pass@1) for Magistral Medium compared to its base model using RL alone.
- Maintains or improves multimodal understanding and instruction following despite being trained purely on textual reasoning data.
- Magistral Small achieves strong performance with cold-start data from Magistral Medium, released under Apache 2.0.
Breakthrough Assessment
8/10
Strong proof-of-concept that pure RL can drive massive reasoning gains (50% on AIME) without distillation, backed by a practical recipe for multilingual alignment and scalable infrastructure.