📝 Paper Summary
Reinforcement Learning for LLMs
Reasoning Models
Long-Context LLMs
Kimi k1.5 scales reinforcement learning by optimizing long-context Chain-of-Thought generation, treating context length as a compute budget to improve reasoning without complex tree search or process rewards.
Core Problem
Standard pretraining is limited by the availability of static high-quality data, while prior RL attempts on LLMs have struggled to produce competitive results compared to supervised scaling.
Why it matters:
- Continued scaling of AI intelligence solely through static data is hitting a ceiling.
- Most existing RL approaches rely on complex, brittle components like Monte Carlo Tree Search or dense process reward models which are hard to scale.
- Effective RL could allow models to self-improve by exploring and learning from their own successful reasoning paths.
Concrete Example:
In complex math problems like AIME, standard models often fail because they lack the ability to 'plan' or 'backtrack'. Kimi k1.5 learns to generate long thought sequences (up to 128k context) that explicitly include trial, error, and correction steps, solving problems where single-pass generation fails.
Key Novelty
Simplistic Long-Context RL Framework
- Scales RL context window to 128k tokens, allowing the model to treat 'thinking time' (token length) as a search budget.
- Uses 'partial rollouts' to efficiently manage long trajectory generation by reusing segments of previous thoughts, avoiding full re-generation.
- Simplifies RL by removing value functions and process reward models (PRMs), relying instead on long-context policy optimization with sparse outcome rewards.
Architecture
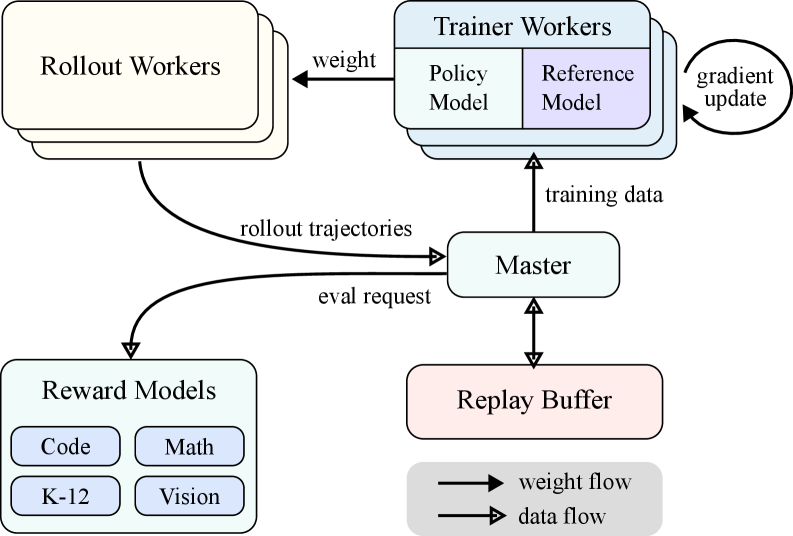
The RL training system architecture focusing on the 'Partial Rollout' mechanism.
Evaluation Highlights
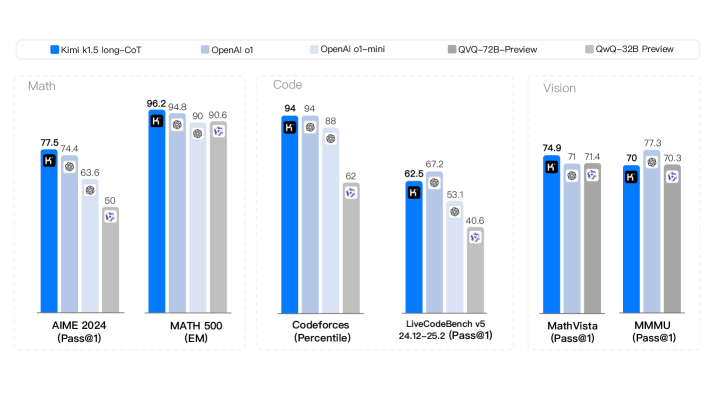
- Matches OpenAI o1 performance on AIME (77.5) and MATH 500 (96.2).
- Achieves 94th percentile on Codeforces, demonstrating strong coding capability.
- long2short distillation improves short-CoT models significantly, outperforming GPT-4o and Claude Sonnet 3.5 by large margins (e.g., +550% relative gain on some metrics).
Breakthrough Assessment
9/10
Demonstrates that simple RL techniques scaled to massive context lengths can match complex proprietary systems like OpenAI o1, establishing a viable alternative to process-reward-heavy approaches.