📝 Paper Summary
Large Language Model Pre-training
Agentic AI
Reinforcement Learning for LLMs
Kimi K2 is a trillion-parameter MoE model trained using a novel stable optimizer (MuonClip) and aligned via large-scale synthetic agentic data and reinforcement learning to excel at reasoning and tool use.
Core Problem
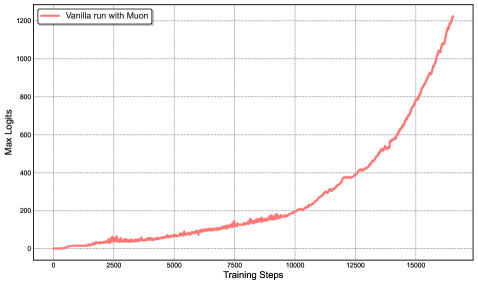
Training massive models with token-efficient optimizers like Muon causes instability (loss spikes) due to exploding attention logits, while post-training for agents lacks high-quality, scalable trajectories.
Why it matters:
- Standard optimizers like AdamW are less token-efficient than Muon, but Muon's instability prevents scaling to trillion-parameter models.
- High-quality human data for complex agentic tasks (planning, tool use) is scarce and expensive to collect manually.
- Static imitation learning fails to teach models self-correction and adaptation in dynamic environments, which are essential for agentic intelligence.
Concrete Example:
When training a mid-scale MoE model with vanilla Muon, maximum attention logits quickly exceed 1000, causing immediate loss spikes and divergence. MuonClip constrains these logits, allowing stable training without spikes.
Key Novelty
MuonClip Optimizer & Agentic RL Pipeline
- Introduces MuonClip, which combines the Muon optimizer with a 'QK-Clip' mechanism that rescales query/key weights only when attention logits grow too large, preventing instability without hurting performance.
- Implements a large-scale synthetic data pipeline that generates verifiable agentic trajectories (tool use) via simulation, effectively creating its own training data.
- Uses a reinforcement learning framework combining verifiable rewards (like passing code tests) with self-critique rubrics to align the model on open-ended tasks.
Architecture
Conceptual flow of the Kimi K2 architecture emphasizing the MoE and MLA components.
Evaluation Highlights
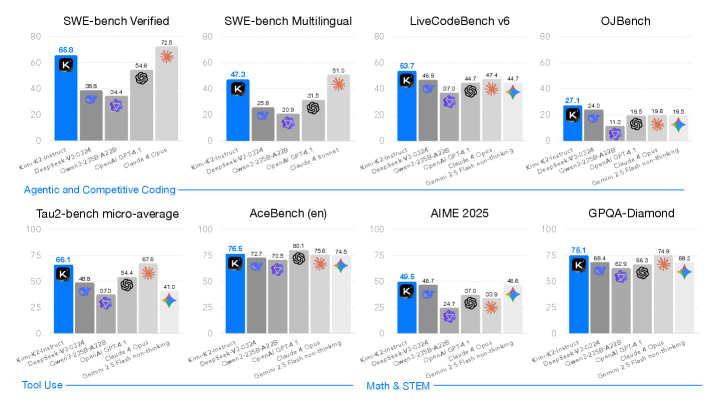
- Obtains 66.1 on Tau2-Bench and 76.5 on ACEBench (En), surpassing most open and closed-source baselines in non-thinking settings.
- Achieves 65.8 on SWE-Bench Verified and 47.3 on SWE-Bench Multilingual, demonstrating strong software engineering capabilities.
- Scores 75.1 on GPQA-Diamond and 49.5 on AIME 2025, showing robust general reasoning performance comparable to top-tier models like Claude 3.5 Sonnet.
Breakthrough Assessment
9/10
Successfully scales Muon optimization to 1T+ parameters (a significant engineering feat) and achieves SOTA open-source performance on agentic benchmarks, closing the gap with top closed models.