📝 Paper Summary
Mixture-of-Experts (MoE) Architectures
Large Language Model Scaling
Efficient Transformer Architectures
DeepSeekMoE improves expert specialization by splitting experts into smaller, more numerous units and dedicating specific shared experts to common knowledge, matching dense model performance with far less compute.
Core Problem
Conventional MoE architectures suffer from knowledge hybridity (experts cover too many diverse topics) and redundancy (multiple experts learn the same common knowledge), limiting specialization.
Why it matters:
- Knowledge hybridity forces single experts to learn conflicting or unrelated concepts, reducing their effectiveness.
- Redundancy wastes parameter capacity as multiple experts duplicate common linguistic knowledge.
- These issues prevent MoE models from reaching their theoretical performance upper bounds compared to dense models.
Concrete Example:
In a standard MoE with only 8 experts, a single expert might handle tokens for both 'coding' and 'creative writing'. Because it must learn both, it specializes in neither. Meanwhile, basic grammar rules (common knowledge) might be duplicated across all 8 experts, wasting capacity.
Key Novelty
DeepSeekMoE (Fine-Grained Segmentation + Shared Experts)
- Fine-Grained Expert Segmentation: Splits standard experts into many smaller ones (e.g., 1 expert → 4 smaller experts) and activates more of them, exponentially increasing routing flexibility without increasing compute.
- Shared Expert Isolation: Dedicates specific experts to be always activated for every token, capturing common knowledge (like syntax) so routed experts can focus solely on specialized contexts.
Architecture
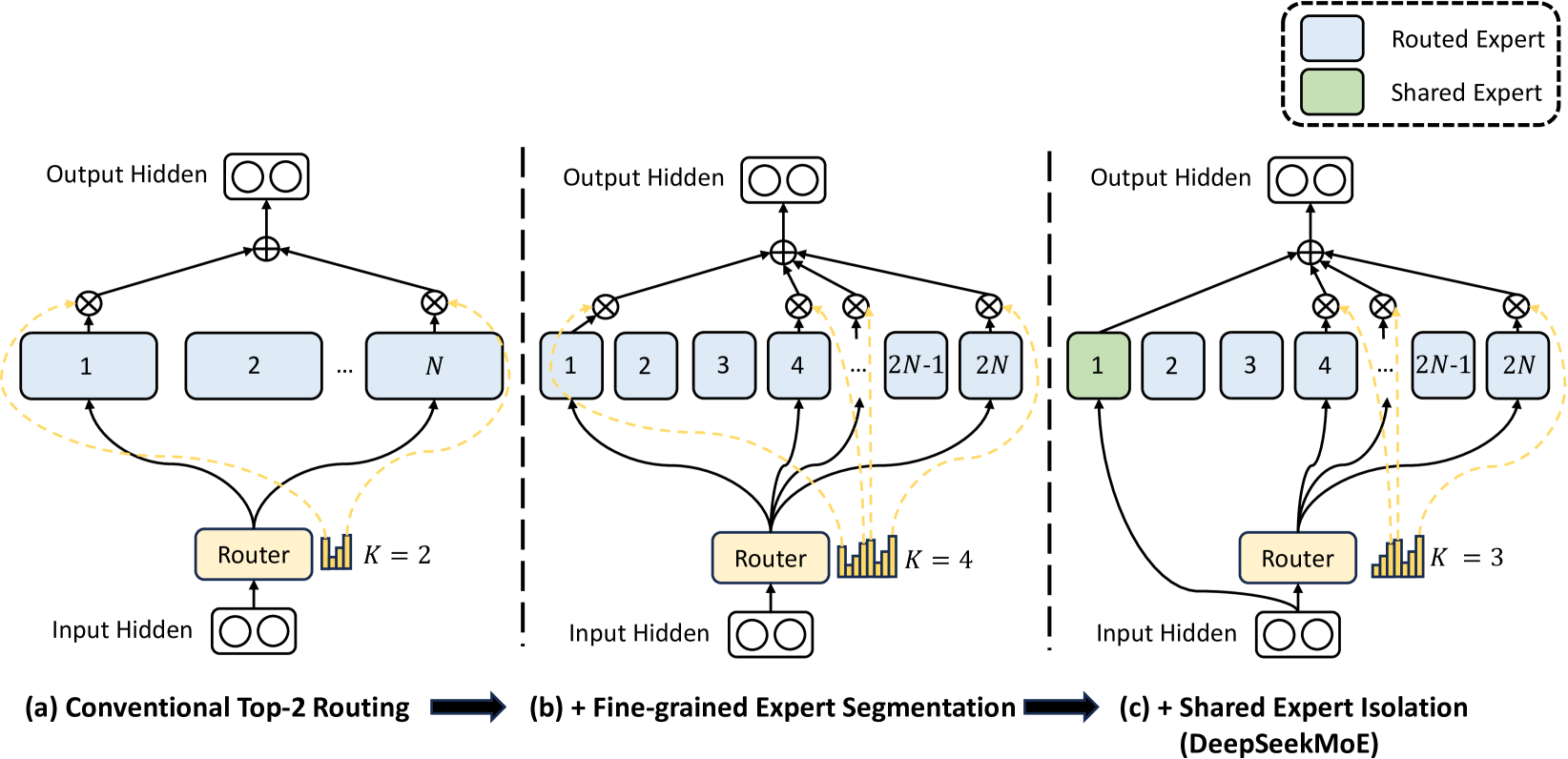
Comparison of Traditional MoE vs. DeepSeekMoE architecture strategies.
Evaluation Highlights
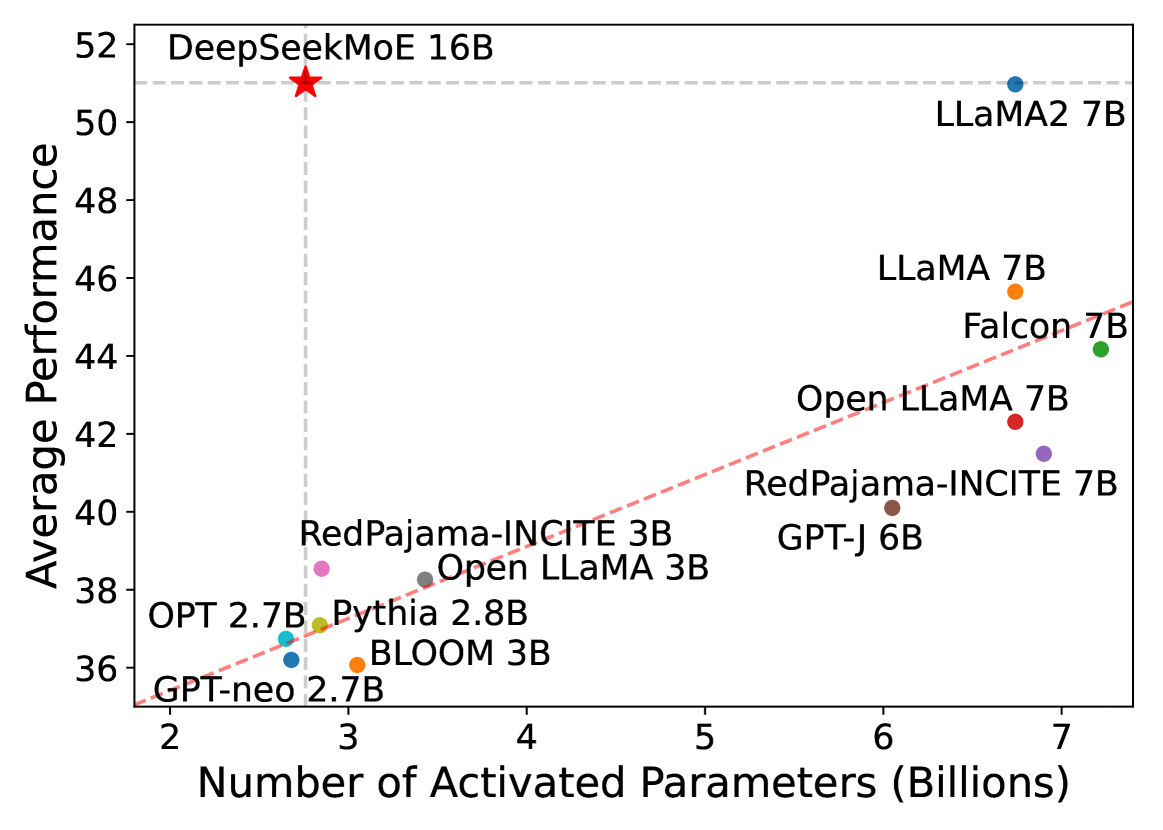
- DeepSeekMoE 16B achieves comparable performance to LLaMA2 7B with only ~40% of the active computation (3.5B active parameters vs 7B).
- DeepSeekMoE 2B matches the performance of the larger GShard 2.9B baseline despite using significantly fewer parameters and compute.
- DeepSeekMoE 2B nearly matches the performance of a dense 2B model, effectively closing the gap between sparse and dense architectures at this scale.
Breakthrough Assessment
8/10
Significant architectural refinement for MoEs. The combination of fine-grained experts and shared experts addresses fundamental routing inefficiencies, enabling MoEs to truly match dense model quality with massive compute savings.