📝 Paper Summary
Mathematical reasoning in LLMs
Reinforcement Learning for reasoning
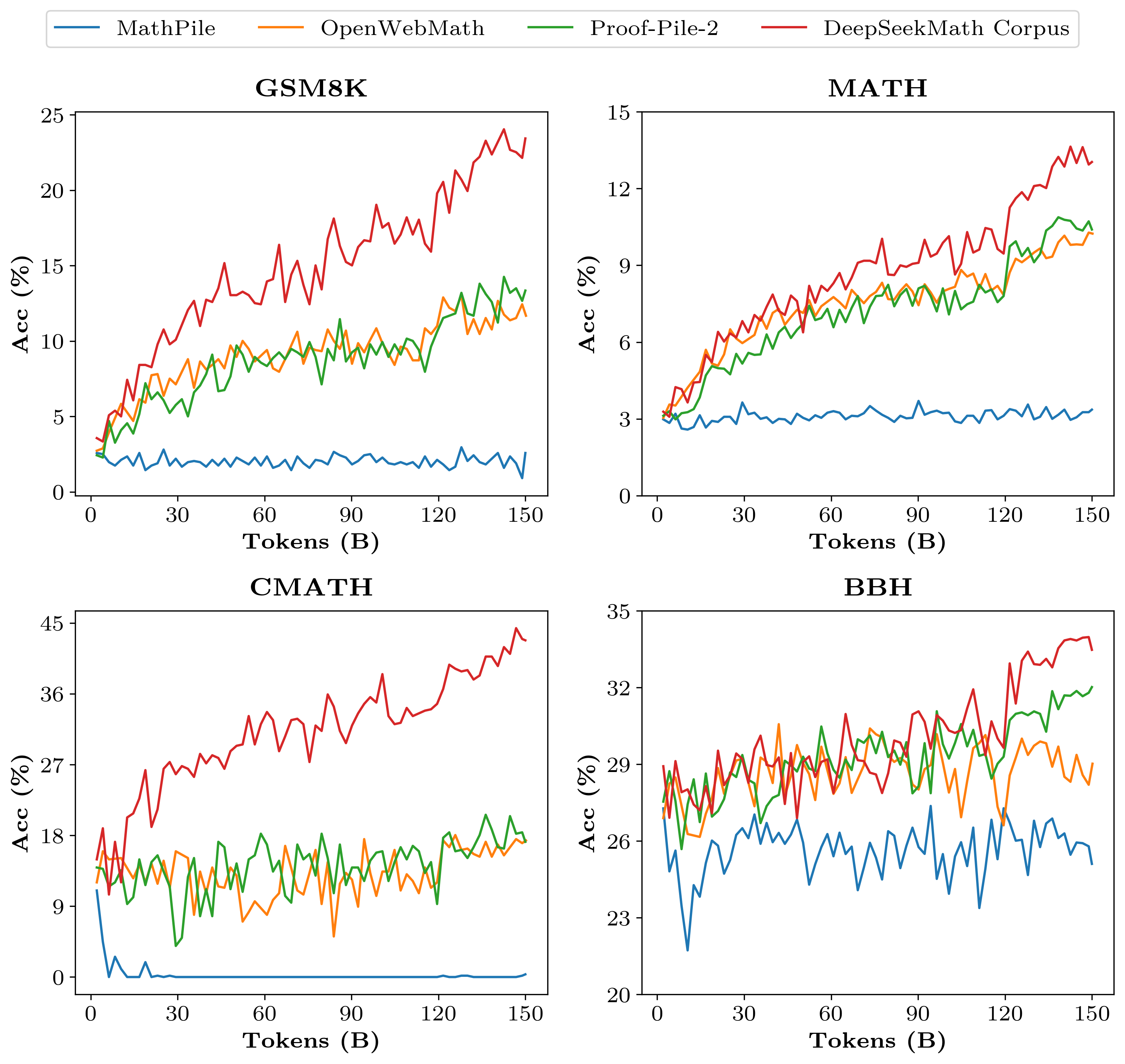
Data curation for pre-training
DeepSeekMath achieves state-of-the-art open-source mathematical reasoning by pre-training on 120B high-quality math tokens mined from Common Crawl and applying a novel critic-free reinforcement learning algorithm (GRPO).
Core Problem
Open-source language models significantly trail behind proprietary models like GPT-4 and Gemini-Ultra in mathematical reasoning due to insufficient high-quality pre-training data and inefficient reinforcement learning methods.
Why it matters:
- Mathematical reasoning is a complex, structured task where standard LLMs struggle without domain-specific training
- Existing open-source math datasets are small (e.g., OpenWebMath is 13.6B tokens) compared to proprietary efforts
- Standard PPO reinforcement learning requires a memory-intensive value function (critic) model, making it computationally expensive to scale
Concrete Example:
Existing open-source base models like Llemma-34B achieve only 25.3% on the MATH benchmark. DeepSeekMath-Base 7B, trained on the new corpus, reaches 36.2%, and with GRPO reinforcement learning, improves to 51.7%, solving problems where base models fail to generate correct reasoning chains.
Key Novelty
DeepSeekMath Corpus & Group Relative Policy Optimization (GRPO)
- Constructs a massive 120B token math corpus by iteratively training a fastText classifier to mine Common Crawl, using OpenWebMath as a seed and refining via human annotation
- Introduces GRPO, a reinforcement learning algorithm that removes the critic model entirely; instead of a value function, it estimates baselines from the average score of a group of outputs generated for the same input
- Initializes the math model from a code-trained base (DeepSeek-Coder) rather than a general LLM, leveraging the synergy between coding and mathematical logic
Architecture
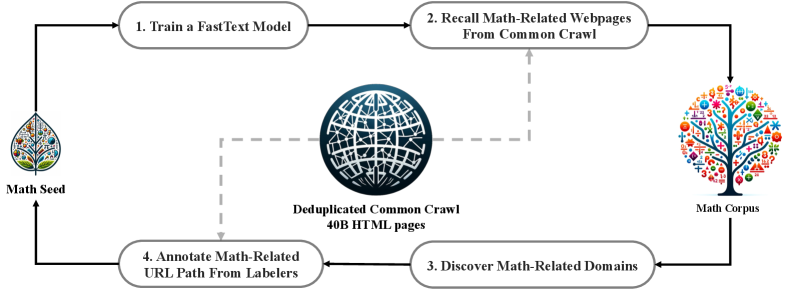
The iterative data collection pipeline for constructing the DeepSeekMath Corpus.
Evaluation Highlights
- DeepSeekMath-RL 7B achieves 51.7% accuracy on the competition-level MATH benchmark, outperforming all open-source 7B models and approaching GPT-4 performance levels
- DeepSeekMath-Base 7B achieves 36.2% on MATH, surpassing the 540B parameter Minerva model (33.6%) despite being ~77x smaller
- GRPO improves GSM8K accuracy from 82.9% (Instruct) to 88.2% and MATH accuracy from 46.8% (Instruct) to 51.7% using only instruction tuning data
Breakthrough Assessment
9/10
Significant breakthrough in both data engineering (proving Common Crawl has massive untapped math data) and RL methodology (GRPO), enabling a 7B model to beat 540B baselines and approach GPT-4.