📝 Paper Summary
Large Language Model Architecture
Efficient Inference
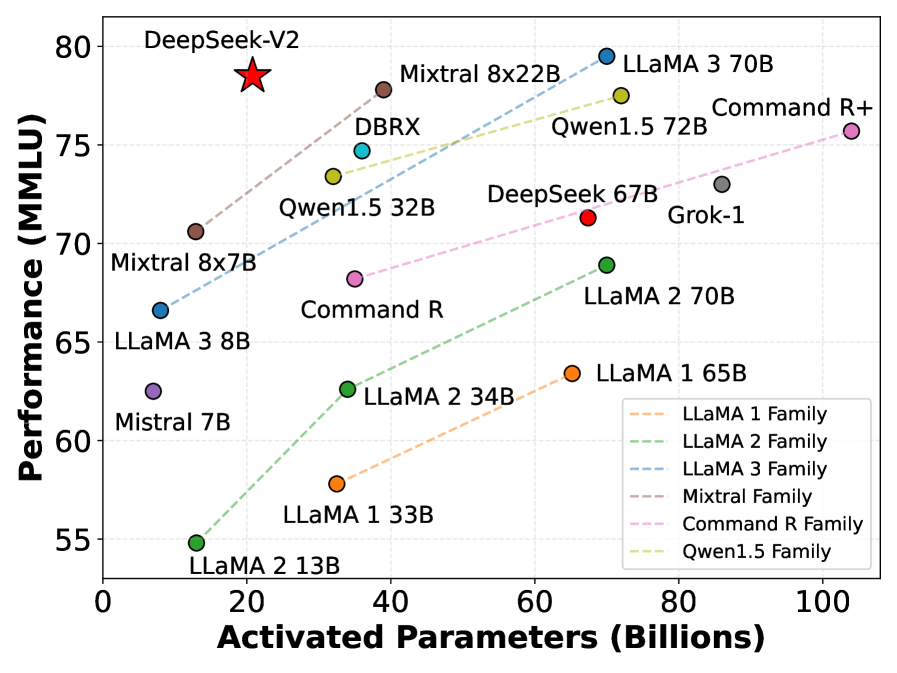
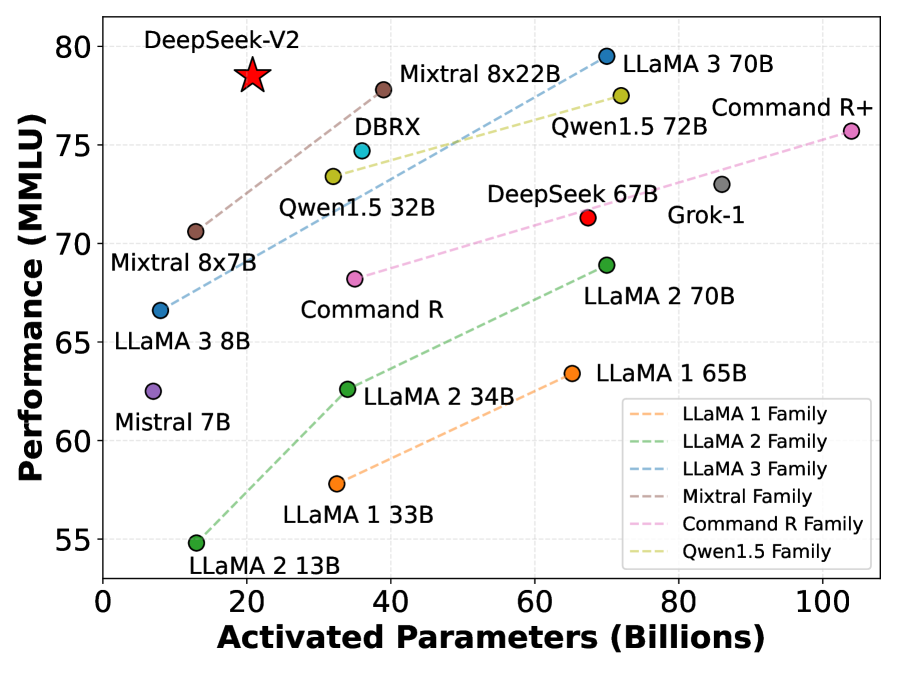
DeepSeek-V2 combines a novel Multi-head Latent Attention mechanism for compressed KV cache with a fine-grained Mixture-of-Experts architecture to achieve top-tier performance at significantly reduced training and inference costs.
Core Problem
Scaling LLMs improves intelligence but drastically increases training costs and creates inference bottlenecks due to large Key-Value (KV) caches, limiting context length and throughput.
Why it matters:
- Heavy KV cache in standard Multi-Head Attention limits maximum batch size and sequence length during deployment
- Training dense models or standard MoEs requires massive computing resources, impeding widespread adoption
- Existing solutions like GQA/MQA reduce cache but compromise performance compared to full Multi-Head Attention
Concrete Example:
In standard Multi-Head Attention, a model must cache keys and values for every token. For a 236B parameter model with long context, this cache grows so large it forces small batch sizes. DeepSeek-V2 compresses this into a low-rank latent vector, reducing cache size by 93.3% while maintaining performance.
Key Novelty
Multi-head Latent Attention (MLA) & DeepSeekMoE
- MLA: Projects Key-Value pairs into a low-rank latent vector instead of storing full heads, drastically shrinking memory usage while recovering head-specific details via up-projection during computation
- DeepSeekMoE: Splits experts into finer grains (more small experts) and isolates 'shared' experts that are always active, allowing specialized experts to learn distinct knowledge without redundancy
Architecture
The architecture of DeepSeek-V2, detailing the Transformer block structure with MLA (Multi-head Latent Attention) and DeepSeekMoE FFN.
Evaluation Highlights
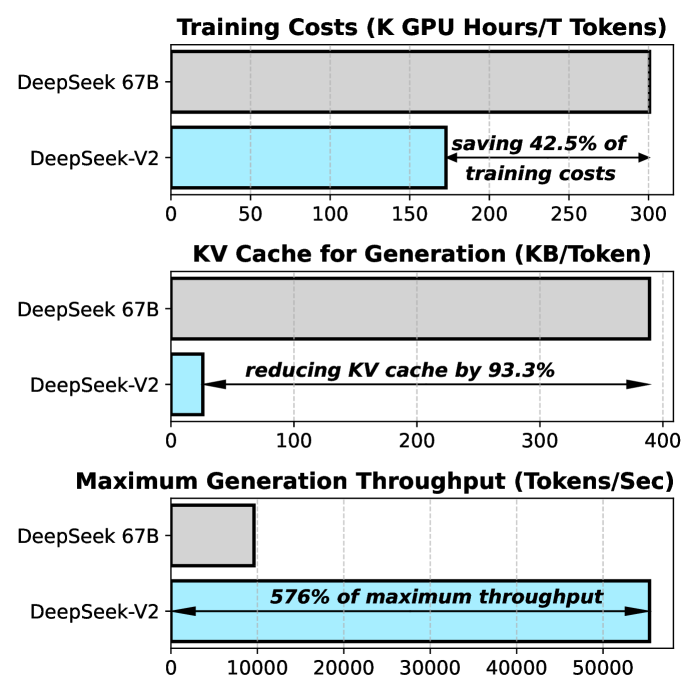
- Saves 42.5% of training costs compared to DeepSeek 67B while achieving significantly stronger performance
- Reduces Key-Value (KV) cache memory by 93.3% compared to standard Multi-Head Attention
- Boosts maximum generation throughput by 5.76 times compared to DeepSeek 67B
Breakthrough Assessment
9/10
Significant architectural innovation in both attention (MLA) and FFN (DeepSeekMoE) that solves major efficiency bottlenecks (KV cache size) without performance trade-offs, setting a new standard for open-source MoE models.