📊 Experiments & Results
Evaluation Setup
Zero-shot evaluation on code generation and math reasoning benchmarks
Benchmarks:
- HumanEval (Python function generation)
- MBPP (Python programming problems)
- LiveCodeBench (Code generation (recent questions))
- SWEBench (Software engineering issues)
- MATH (Competition-level math problems)
- GSM8K (Grade school math)
Metrics:
- Pass@1
- Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| DeepSeek-Coder-V2 achieves state-of-the-art results among open-source models and rivals top closed-source models on standard coding benchmarks. | ||||
| HumanEval | Pass@1 | 79.3 | 90.2 | +10.9 |
| MBPP | Pass@1 | 70.1 | 76.2 | +6.1 |
| LiveCodeBench | Pass@1 | 32.5 | 43.4 | +10.9 |
| In mathematical reasoning, the model shows substantial improvements, rivaling GPT-4o. | ||||
| MATH | Accuracy | 42.0 | 75.7 | +33.7 |
| GSM8K | Accuracy | 80.6 | 94.9 | +14.3 |
| Ablation studies on a smaller 1B model confirm the superiority of the new dataset composition. | ||||
| HumanEval | Pass@1 | 30.5 | 37.2 | +6.7 |
Experiment Figures
Needle In A Haystack (NIAH) test results across varying context lengths up to 128K.
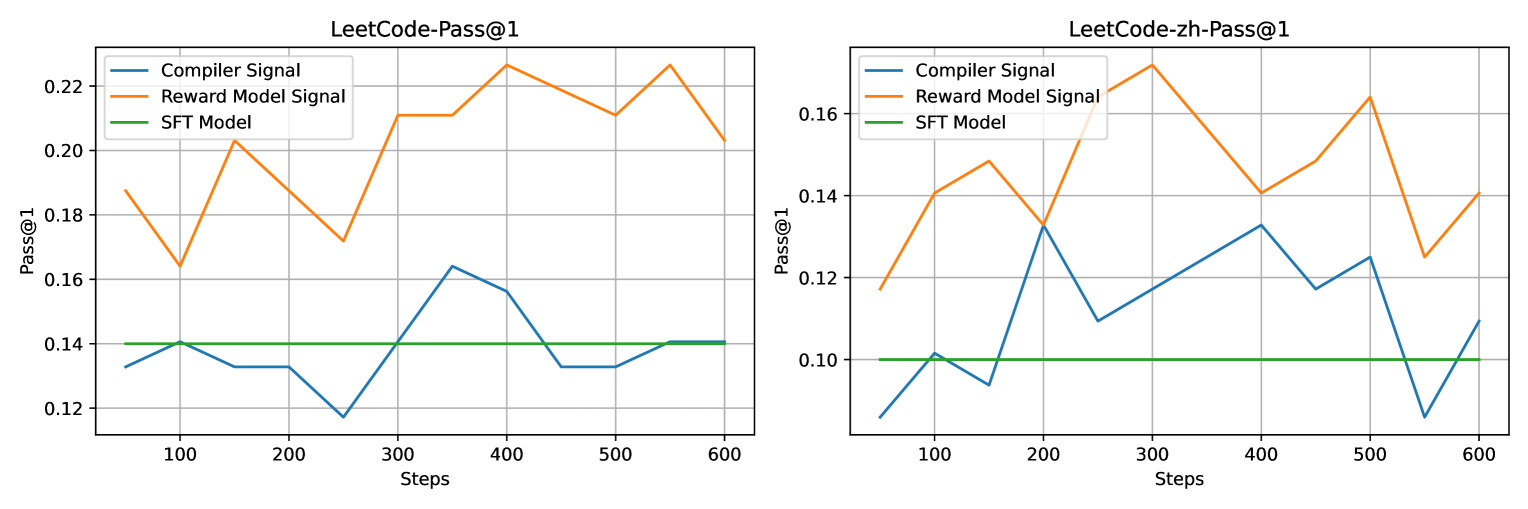
Comparison of RL training signals: Reward Model vs. Raw Compiler Feedback on Leetcode test sets.
Main Takeaways
- DeepSeek-Coder-V2 successfully bridges the gap between open-source and top-tier closed-source models (GPT-4 Turbo) in code and math.
- The mixture-of-experts (MoE) architecture allows for massive parameter scaling (236B) with manageable active parameters (21B).
- Expanding the pre-training corpus to include 338 languages and extensive math data yields significant gains over previous iterations.
- RL alignment using a learned reward model (vs raw compiler feedback) provides robust performance improvements.