📝 Paper Summary
Large Language Model Training
Mixture-of-Experts (MoE)
Efficient Inference
DeepSeek-V3 is a 671B parameter Mixture-of-Experts model that achieves top-tier open-source performance through auxiliary-loss-free load balancing, multi-token prediction training, and highly optimized FP8 training.
Core Problem
Training massive MoE models typically suffers from routing collapse or performance degradation due to auxiliary load-balancing losses, while cross-node communication bottlenecks limit training efficiency at scale.
Why it matters:
- Auxiliary losses used to balance expert load often interfere with the primary objective, degrading model performance
- Communication overhead in cross-node MoE training limits scalability and increases training costs
- Leading closed-source models (like GPT-4) remain significantly ahead of open-source alternatives in reasoning and coding tasks
Concrete Example:
In standard MoE training, if one expert becomes popular, a load-balancing loss forces the router to assign tokens to less relevant experts to even out the load, hurting prediction accuracy. DeepSeek-V3 avoids this trade-off.
Key Novelty
Auxiliary-Loss-Free Load Balancing & Multi-Token Prediction
- Replaces the traditional auxiliary loss with a dynamic bias term added to expert affinity scores; this bias adjusts based on load to ensure balance without altering the gradients of the main objective
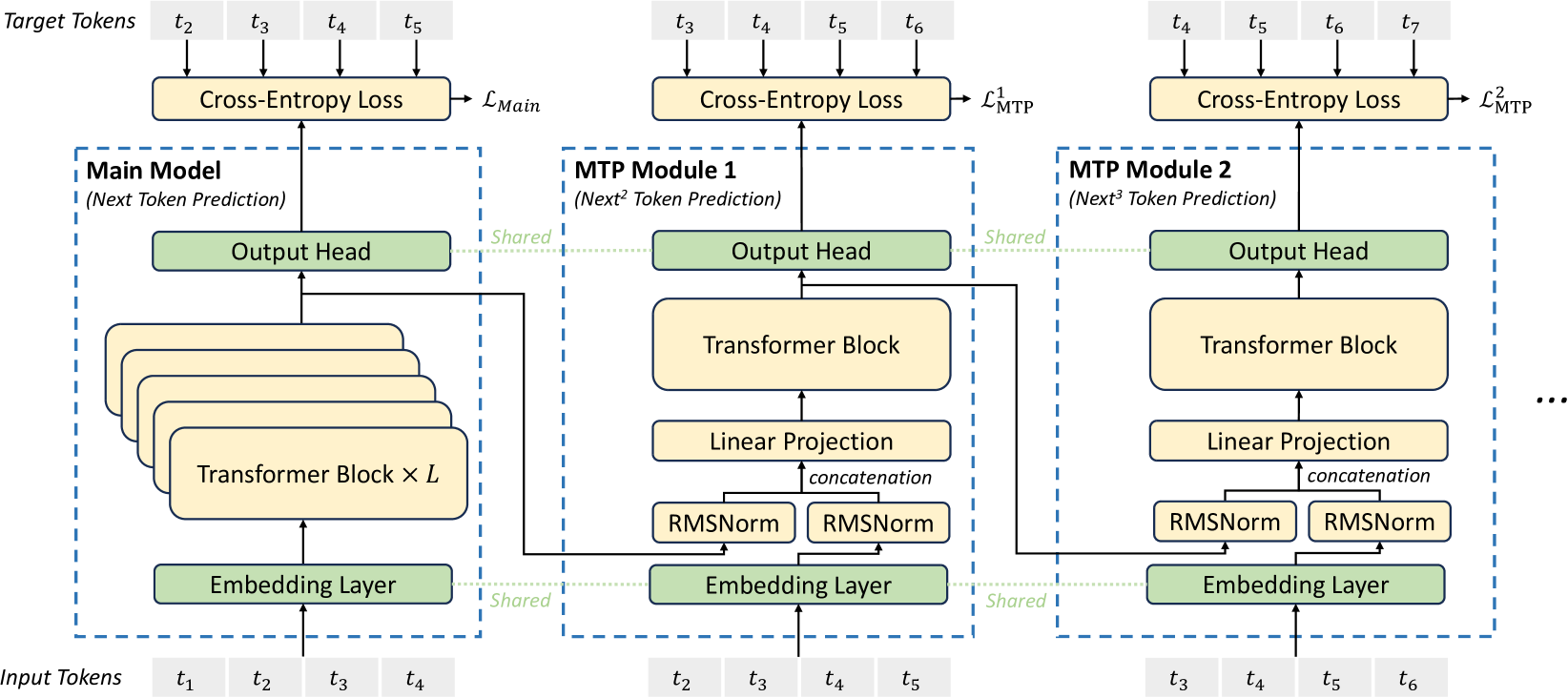
- Utilizes Multi-Token Prediction (MTP) to predict multiple future tokens sequentially at each position, densifying training signals and enabling speculative decoding for faster inference
- Implements DualPipe for pipeline parallelism to overlap computation and communication, enabling efficient scaling
Architecture
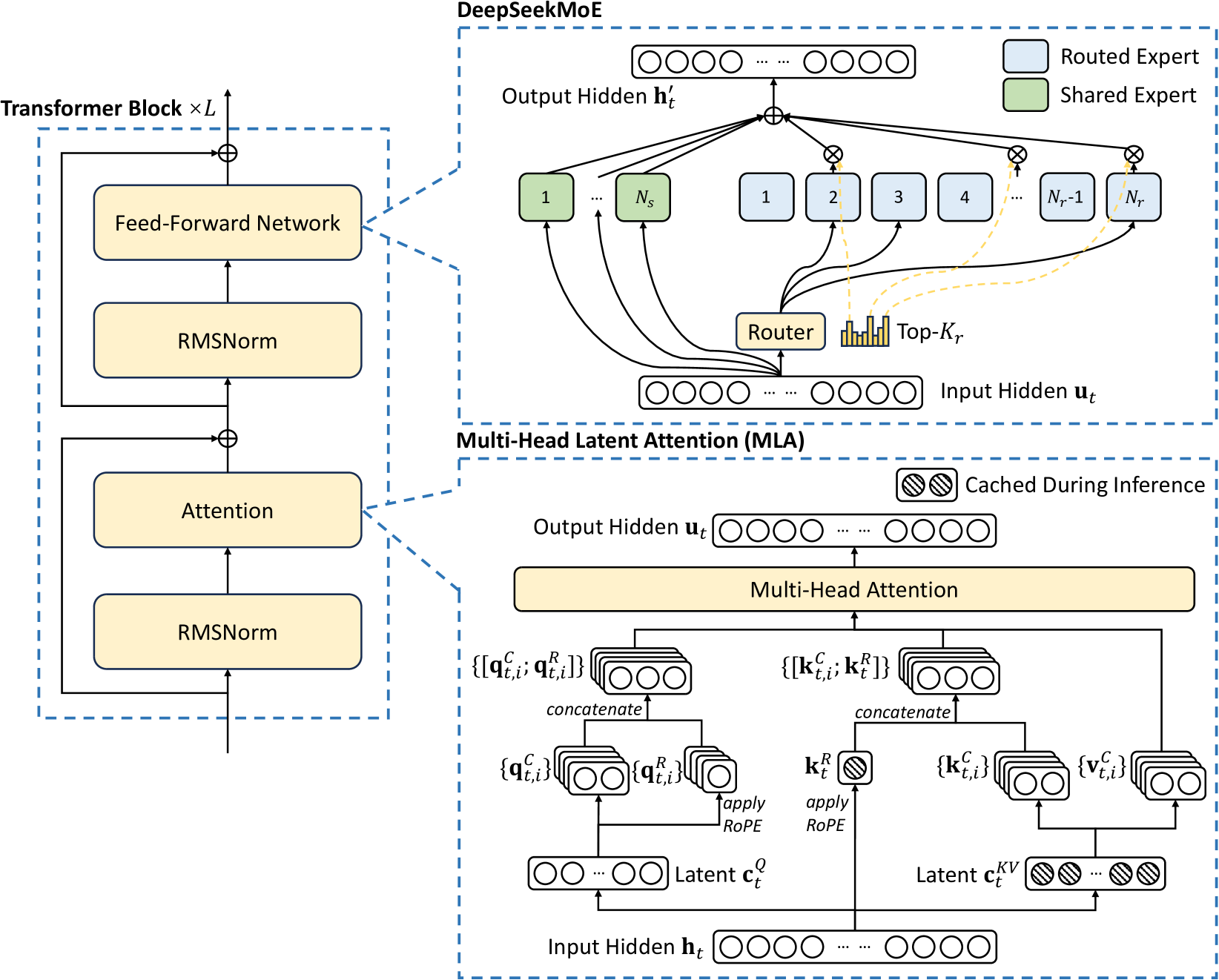
The basic architecture of DeepSeek-V3, highlighting the MLA (Multi-head Latent Attention) mechanism and the DeepSeekMoE Feed-Forward Network structure.
Evaluation Highlights
- Achieves 88.5 score on MMLU, outperforming all other open-source models and comparable to GPT-4o
- Costs only $5.576M (2.788M H800 GPU hours) for full training, significantly lower than comparable distinct closed-source models
- Outperforms o1-preview on MATH-500 benchmark, demonstrating state-of-the-art mathematical reasoning among non-long-CoT models
Breakthrough Assessment
9/10
Delivers GPT-4 class performance at a fraction of the typical training cost through architectural and system-level innovations (FP8, MoE balancing). Sets a new standard for open-source efficiency.