📝 Paper Summary
Semi-supervised learning
Transfer learning
Language modeling
This paper proposes generative pre-training of a language model on diverse unlabeled text followed by discriminative fine-tuning on specific tasks, achieving state-of-the-art results across natural language understanding benchmarks.
Core Problem
Deep learning for NLP typically requires large amounts of labeled data, which is scarce for specific tasks, and existing transfer learning methods using word embeddings fail to capture higher-level semantics.
Why it matters:
- Labeled data is expensive and time-consuming to obtain, limiting applicability in many domains.
- Previous semi-supervised approaches often require substantial task-specific architecture changes.
- Effective utilization of abundant unlabeled text could significantly improve performance and generalization.
Concrete Example:
Tasks like semantic similarity have no inherent sentence ordering. Standard models require specific architectures to handle this. The proposed approach uses traversal-style input transformations (concatenating sentences with delimiters) to process them with a single pre-trained model without architecture changes.
Key Novelty
Generative Pre-Training (GPT)
- Train a high-capacity Transformer model to predict the next token on a massive corpus of unlabeled text (BooksCorpus) to learn universal language representations.
- Transfer this pre-trained model to specific downstream tasks by fine-tuning with a supervised objective, using simple input transformations (like adding delimiters) rather than complex task-specific architectures.
Architecture
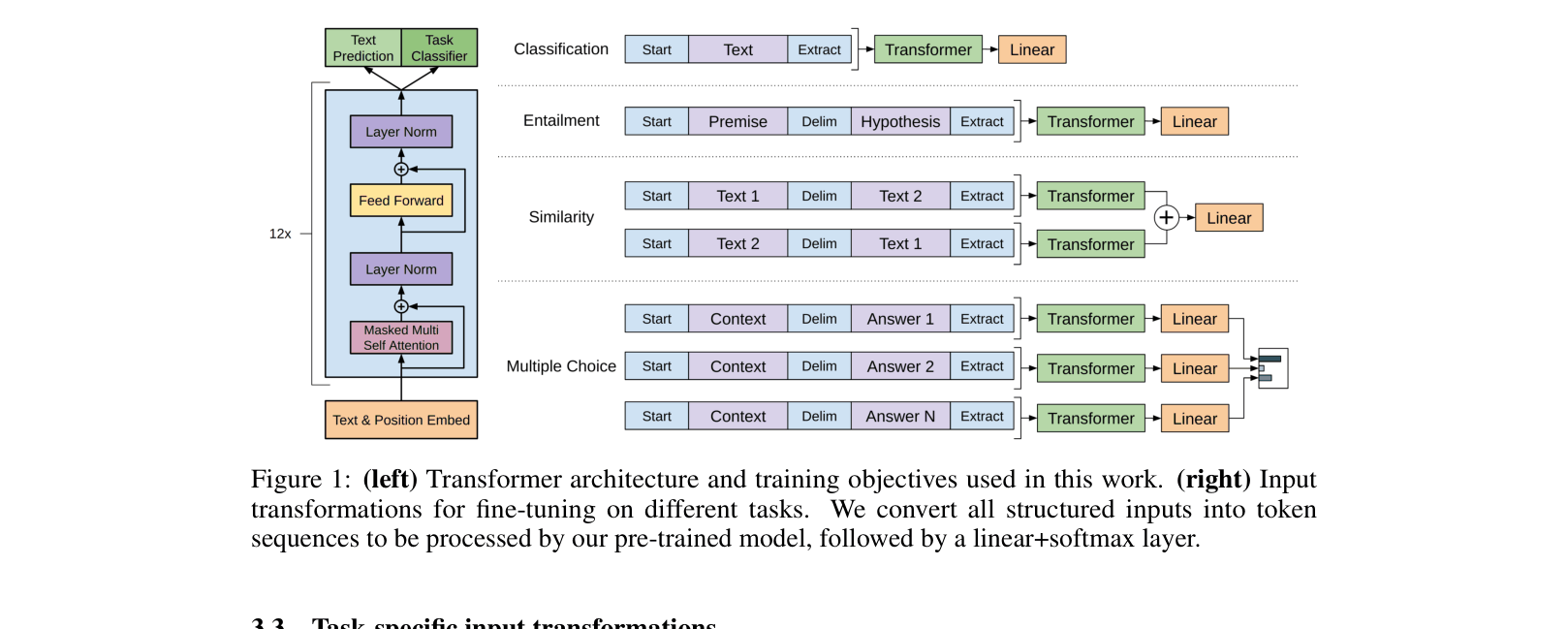
The Transformer architecture used (left) and the task-specific input transformations (right) for fine-tuning on different task types (Classification, Entailment, Similarity, Multiple Choice).
Evaluation Highlights
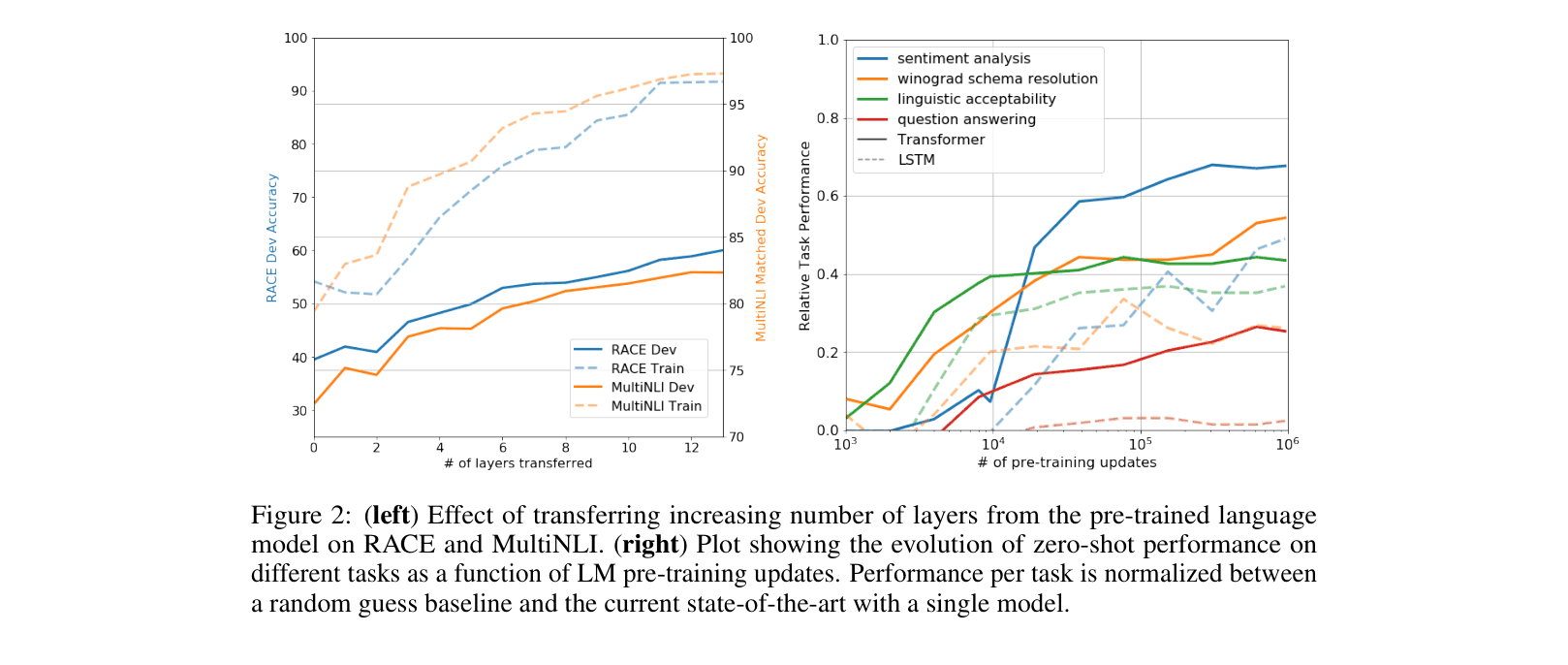
- Significantly improved upon the state of the art in 9 out of 12 tasks studied.
- Achieved 8.9% absolute improvement on commonsense reasoning (Story Cloze Test) and 5.7% on question answering (RACE).
- Attained a score of 45.4 on CoLA (linguistic acceptability), a massive jump over the previous best result of 35.0.
Breakthrough Assessment
10/10
This paper (GPT-1) established the foundational paradigm of modern NLP: large-scale unsupervised pre-training followed by fine-tuning, shifting the field away from task-specific architectures.