📊 Experiments & Results
Evaluation Setup
Zero-shot evaluation on diverse NLP tasks using Language Modeling (perplexity) or generation capability.
Benchmarks:
- Children's Book Test (CBT) (Cloze test (Named Entities, Common Nouns))
- LAMBADA (Long-range dependency modeling / Word prediction)
- Winograd Schema Challenge (Commonsense reasoning / Ambiguity resolution)
- CoQA (Reading Comprehension / Question Answering)
- CNN/Daily Mail (Summarization)
- WMT-14 English-French (Machine Translation)
- Penn Treebank (PTB) (Language Modeling)
- WikiText-103 (Language Modeling)
Metrics:
- Perplexity (PPL)
- Accuracy (ACC)
- F1 Score
- BLEU
- Bits per Character/Byte (BPC/BPB)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| GPT-2 establishes new State-of-the-Art (SOTA) results on the majority of zero-shot language modeling benchmarks, demonstrating superior distribution estimation. | ||||
| LAMBADA | Perplexity (PPL) | 99.8 | 8.63 | -91.17 |
| LAMBADA | Accuracy | 59.23 | 63.24 | +4.01 |
| Penn Treebank (PTB) | Perplexity (PPL) | 46.54 | 35.76 | -10.78 |
| WikiText-103 | Perplexity (PPL) | 18.3 | 17.48 | -0.82 |
| Performance on downstream tasks shows competitive results against supervised baselines in zero-shot settings, particularly in Reading Comprehension and Commonsense Reasoning. | ||||
| CoQA | F1 | 55.0 | 55.0 | 0.0 |
| Winograd Schema Challenge | Accuracy | 63.7 | 70.7 | +7.0 |
| WMT-14 French-English | BLEU | 15.1 | 11.5 | -3.6 |
| Children's Book Test (CBT) - Common Nouns | Accuracy | 85.7 | 93.30 | +7.60 |
Experiment Figures
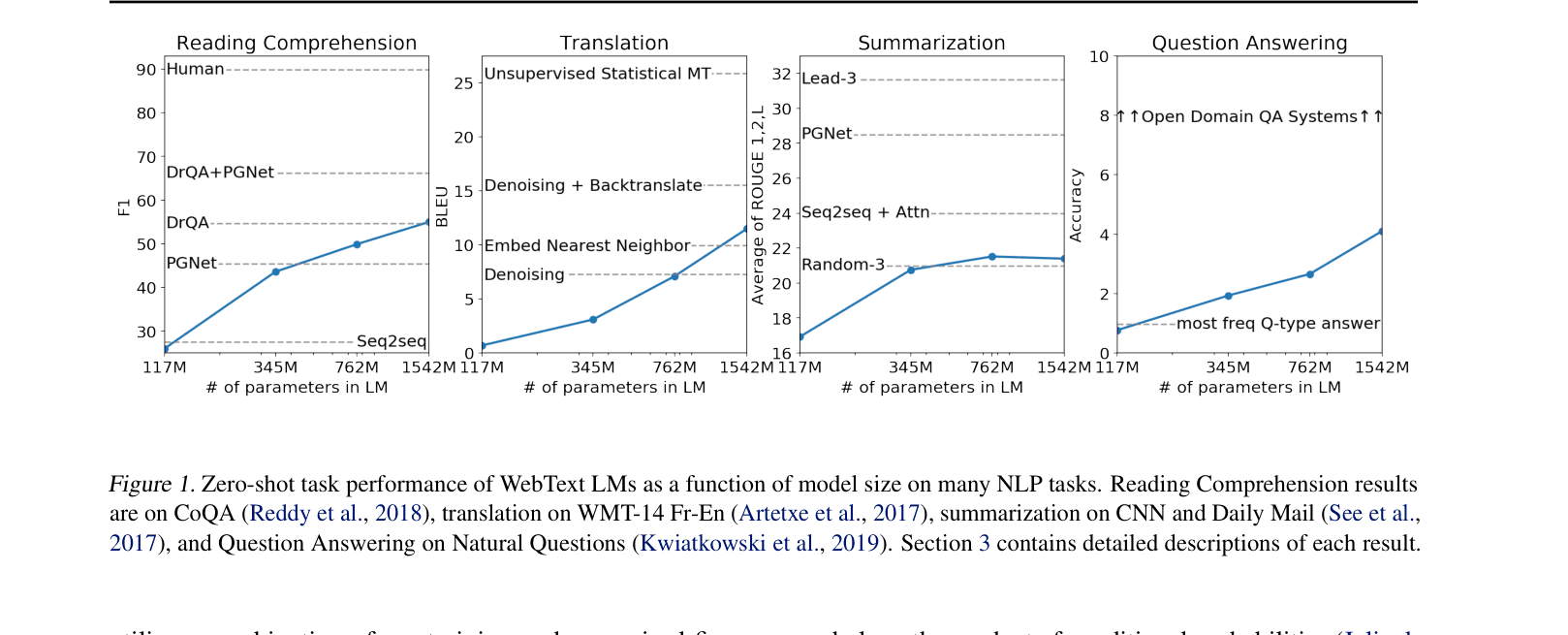
Zero-shot task performance of WebText LMs as a function of model size on many NLP tasks (Reading Comprehension, Translation, Summarization, QA).
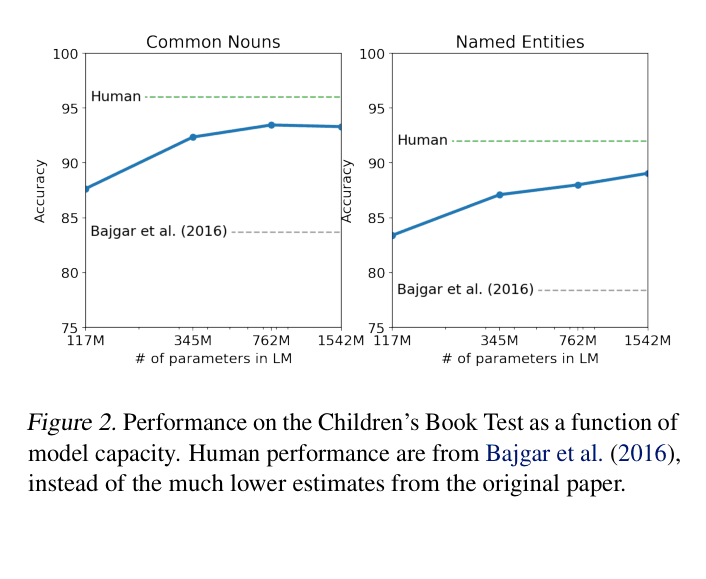
Performance on the Children's Book Test (Common Nouns and Named Entities) as a function of model capacity compared to human performance.
Main Takeaways
- Zero-shot performance improves log-linearly with model capacity (size) across most tasks.
- The model implicitly learns tasks like translation and summarization from naturally occurring demonstrations in WebText (e.g., 'English sentence = French sentence' or 'TL;DR').
- While effective for zero-shot transfer, the model still significantly underperforms supervised state-of-the-art on complex tasks like Question Answering and Translation.
- Data overlap analysis suggests performance gains are largely genuine generalization, not just memorization (overlap between WebText and test sets is generally low, ~3.2%).