📝 Paper Summary
Large Language Models (LLMs)
Few-Shot Learning
In-Context Learning
Scaling autoregressive language models to 175 billion parameters enables them to perform a wide variety of NLP tasks via in-context learning without any gradient updates or fine-tuning.
Core Problem
Standard NLP paradigms require large task-specific datasets for fine-tuning, limiting applicability and potentially exploiting spurious correlations rather than true generalization.
Why it matters:
- Collecting large labeled datasets for every new task is impractical and limits the versatility of language systems
- Models fine-tuned on narrow distributions often generalize poorly out-of-distribution
- Humans can learn new language tasks from just a few examples or instructions, a capability current NLP systems largely lack
Concrete Example:
To perform a task like correcting grammar or critiquing a story, standard approaches require thousands of labeled examples. Humans only need a brief instruction (e.g., 'tell me if this sentence is happy or sad').
Key Novelty
GPT-3 (175B parameter In-Context Learner)
- Scales model size to 175 billion parameters (10x previous non-sparse models) to test if meta-learning abilities improve with scale
- Uses 'in-context learning' where the model is conditioned on a natural language instruction and/or a few demonstrations within its context window at inference time
- Evaluates performance strictly without gradient updates, relying solely on the pre-trained model's pattern recognition abilities
Architecture
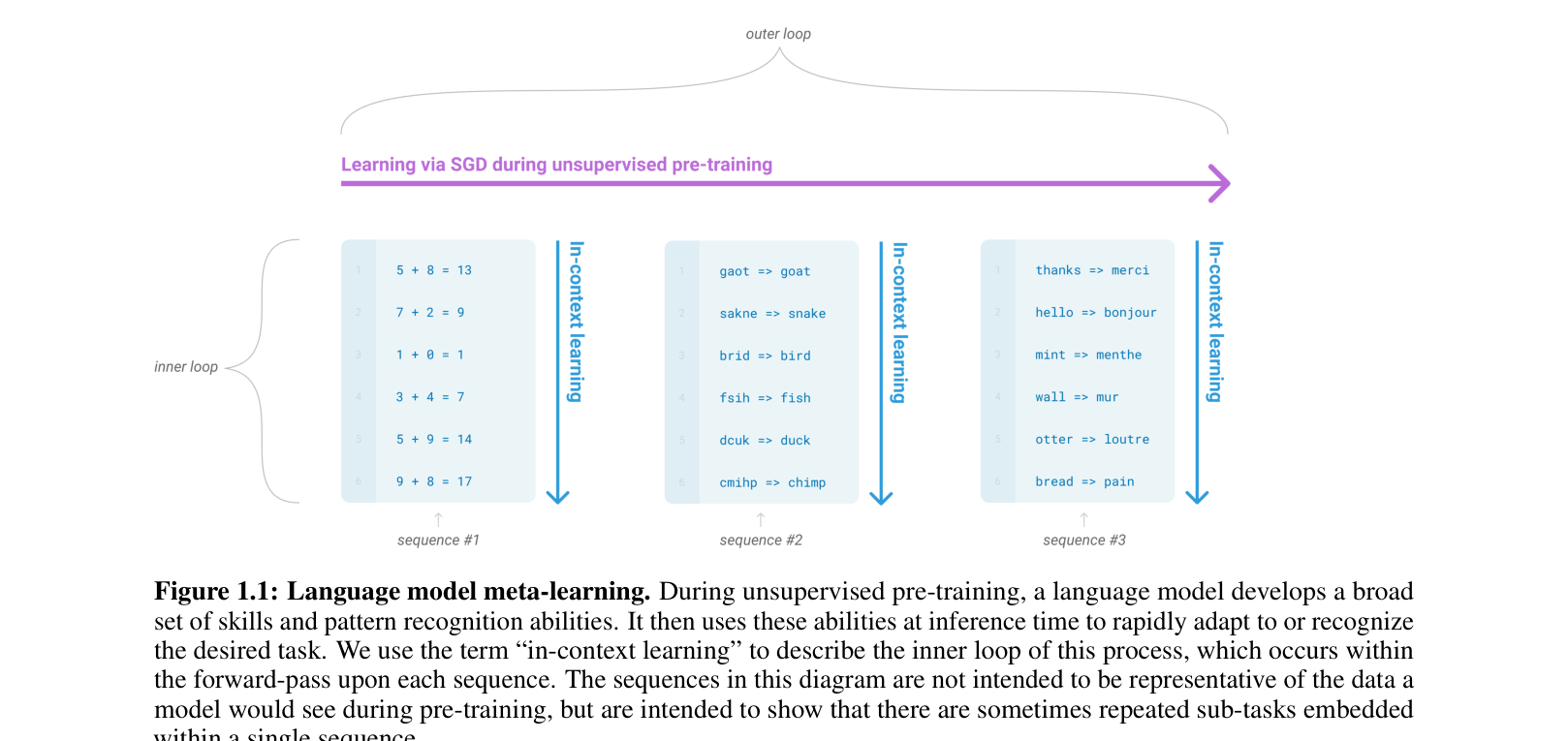
Conceptual diagram of Language Model Meta-Learning (In-Context Learning)
Evaluation Highlights
- Achieves 86.4% accuracy on LAMBADA (few-shot), improving state-of-the-art by over 18%
- Generates synthetic news articles that human evaluators struggle to distinguish from human-written ones (difficulty rating approx 50/100)
- Matches SOTA open-domain fine-tuning performance on TriviaQA in the few-shot setting (71.2% accuracy)
Breakthrough Assessment
10/10
Defined the modern era of Generative AI. Demonstrated that massive scale leads to emergent in-context learning abilities, allowing models to solve tasks without fine-tuning.