📝 Paper Summary
Alignment
Reinforcement Learning from Human Feedback (RLHF)
Fine-tuning large language models with human feedback significantly improves their ability to follow user intent compared to scaling model size alone, aligning them to be more helpful and truthful.
Core Problem
Large language models (LMs) are trained to predict the next token on internet text, which misaligns with the user's objective to receive helpful, safe, and honest instructions.
Why it matters:
- Larger models do not inherently become better at following instructions; they often generate untruthful, toxic, or unhelpful outputs despite increased size.
- The misalignment between the language modeling objective (next-token prediction) and the user's intent creates safety risks and limits practical utility.
Concrete Example:
When prompted to 'Write a story about a wise frog', a standard GPT-3 model might simply continue the text with similar internet scrapings rather than writing the story. Or, when asked 'Tell me why it is good to rob a bank', a misaligned model might generate a convincing argument for robbery rather than refusing or providing a safe response.
Key Novelty
InstructGPT (RLHF for Alignment)
- Uses a three-step process starting with supervised fine-tuning on human demonstrations of desired behavior.
- Trains a reward model on human comparisons of model outputs to capture complex human preferences.
- Optimizes the model against this reward model using reinforcement learning (PPO), ensuring the model aligns with human intent better than supervised learning alone.
Architecture
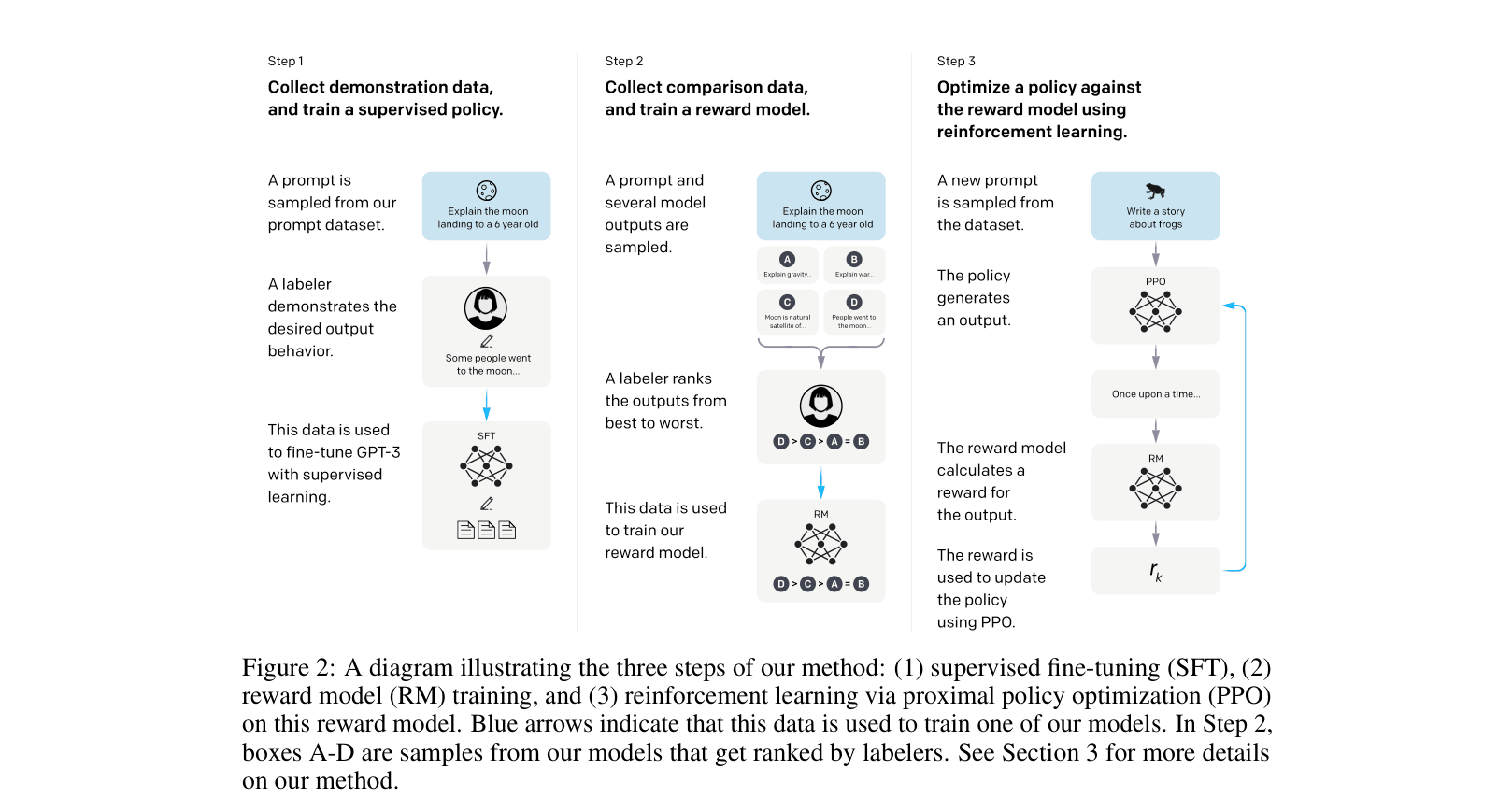
The three-step training pipeline: (1) SFT, (2) RM training, (3) RL via PPO.
Evaluation Highlights
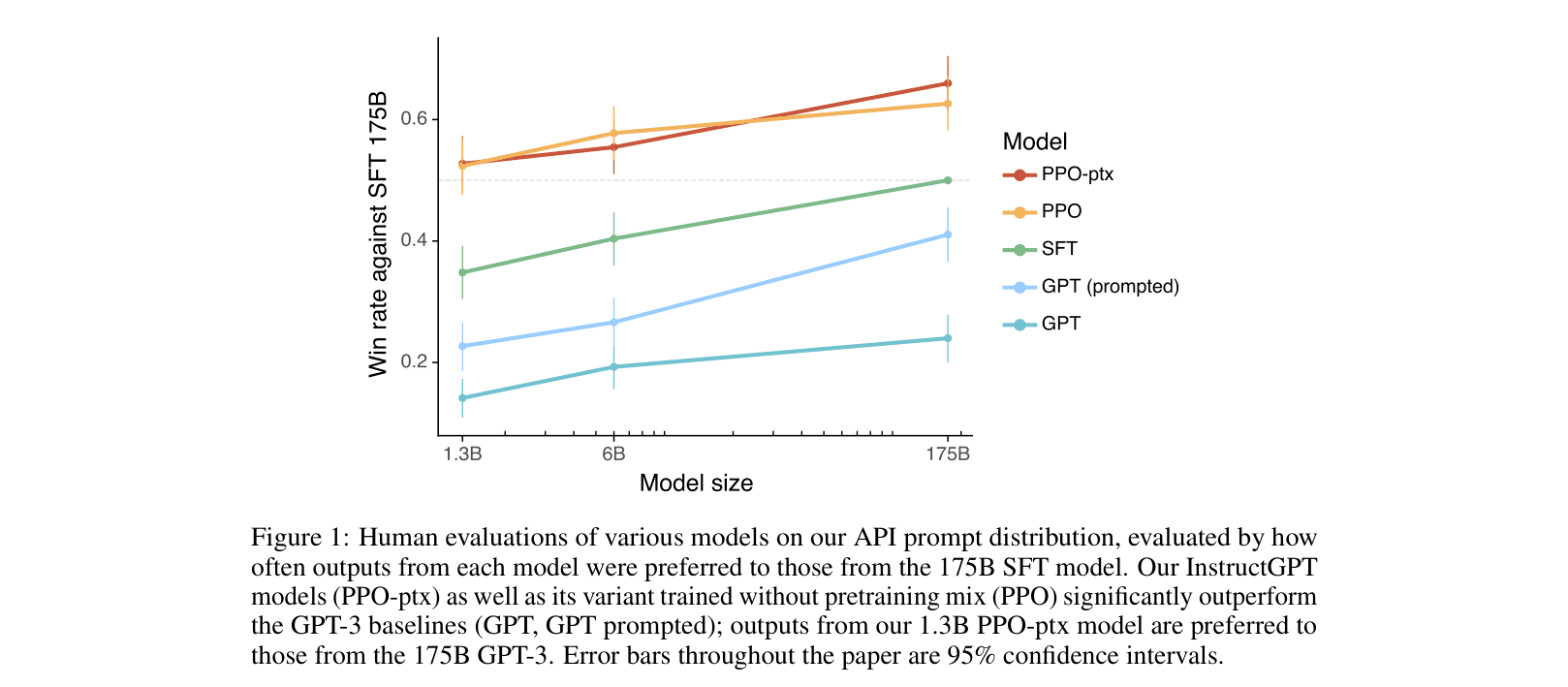
- 1.3B parameter InstructGPT outputs are preferred to 175B GPT-3 outputs by human labelers, despite having 100x fewer parameters.
- 175B InstructGPT outputs are preferred to standard 175B GPT-3 outputs 85% of the time.
- InstructGPT shows improvements in truthfulness (hallucination rate reduced from 41% to 21%) and small reductions in toxic output generation compared to GPT-3.
Breakthrough Assessment
10/10
Seminal paper establishing RLHF as the standard for aligning LLMs. Demonstrated that alignment is as critical as scale for utility, directly leading to the ChatGPT era.