📝 Paper Summary
Universal Multimodal Embeddings (UME)
Multimodal Retrieval
Instruction-following Embeddings
The Think-Then-Embed framework enhances multimodal embedding models by generating explicit reasoning traces before encoding, allowing the model to better understand complex instructions like visual grounding and VQA.
Core Problem
Existing Multimodal Large Language Models (MLLMs) used for embeddings treat the model solely as an encoder, overlooking its generative reasoning capacity required for complex, instruction-heavy tasks.
Why it matters:
- Current benchmarks like MMEB-v2 include tasks (VQA, visual grounding) where simple encoding fails to capture the necessary nuance
- Treating MLLMs only as encoders wastes their pre-trained generative capabilities
- Without reasoning, models struggle to differentiate between similar visual inputs based on complex user instructions (e.g., 'second closest vehicle')
Concrete Example:
In a RefCOCO task asking for the 'vehicle second closest to camera', a standard encoder might just match the query to any vehicle. TTE first reasons that the target has 'bright yellow on the upper half', enabling precise retrieval of the correct specific region.
Key Novelty
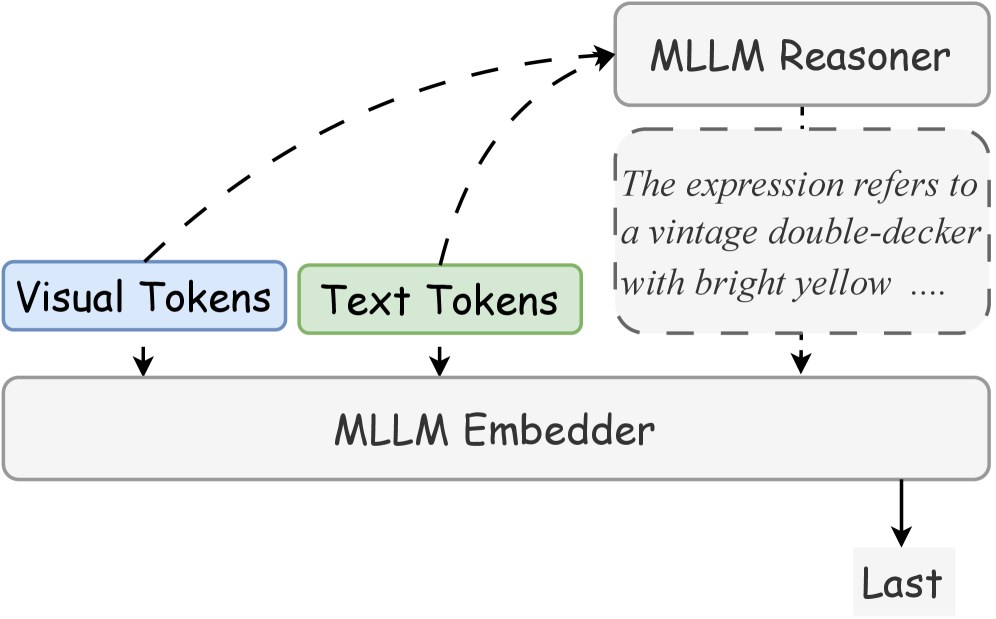
Think-Then-Embed (TTE) Framework
- Introduces an intermediate 'thinking' stage where a reasoner generates an Embedding-Centric Reasoning (ECR) trace (e.g., detailed descriptions or step-by-step logic) before the embedding is created
- Conditions the final embedding on both the original query/image and this generated reasoning trace, bridging the gap between generative reasoning and representation learning
- Proposes a unified architecture where a single MLLM backbone acts as both reasoner and embedder via a two-stage training process with a pluggable embedding head
Architecture

Comparison of Standard Embedding approach vs. Think-Then-Embed (TTE) frameworks (Teacher-Student and Unified).
Evaluation Highlights
- TTEt-7B achieves state-of-the-art score of 71.5% on MMEB-V2, surpassing proprietary models like seed-1.6-embedding
- TTEs-7B (student reasoner) outperforms the VLM2Vec-V2 baseline by 7.4% on MMEB-V1
- TTEt-2B improves over the VLM2Vec-V2 2B baseline by 10.6% on MMEB-V2
Breakthrough Assessment
8/10
Significant performance gains on major benchmarks by successfully integrating Chain-of-Thought into representation learning, a technique previously limited to generation tasks.