📝 Paper Summary
LLM Reasoning
RLHF / Preference Optimization
Self-Improvement
GPO improves LLM reasoning by identifying the single most critical step in a trajectory using advantage estimation and resetting the optimization process to focus specifically on that pivotal moment.
Core Problem
Existing optimization methods like PPO and DPO treat reasoning trajectories as a whole, failing to pinpoint and correct specific intermediate errors that lead to final failure.
Why it matters:
- LLMs frequently make subtle errors in intermediate reasoning steps that cause the entire solution to fail, even if most of the text is fluent
- Optimizing on full trajectories (standard PPO/DPO) is inefficient because the model receives a single reward signal for a long sequence, obscuring which specific step caused the error
- Without targeted correction, models struggle to learn reliable multi-step reasoning for complex math and coding tasks
Concrete Example:
In a date calculation problem ('What is the date 24 hours later?'), the model might correctly identify the start date but misinterpret 'a week ago' in step 2. Standard methods penalize the whole chain; GPO identifies step 2 as the 'critical step' where the error occurred and resets training there.
Key Novelty
Critical Step Reset & Advantage-Weighted Learning
- Segments a reasoning trajectory into steps and uses Monte Carlo estimation to calculate the 'advantage' of each step—identifying the exact moment where success became possible or impossible
- Resets the generation process specifically at this critical step to sample new completions, forcing the model to practice the most pivotal decision point
- Integrates this targeted sampling into both online (PPO-style) and offline (DPO-style) optimization frameworks to weight updates by step importance
Architecture
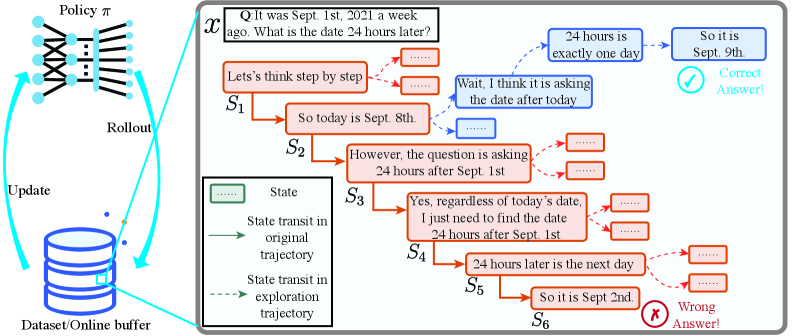
Conceptual illustration of the GPO process using a date calculation example.
Evaluation Highlights
- Significant improvements across 7 reasoning datasets (GSM8K, MATH, etc.) with the DeepSeek-R1-Distill-Qwen-7B base model
- Outperforms standard PPO and DPO baselines, as well as the random-reset method Satori
- Consistent gains in both online (Procedure-I) and offline (Procedure-II) settings, demonstrating the method's versatility as a general optimization strategy
Breakthrough Assessment
8/10
Offers a theoretically grounded and empirically effective method for credit assignment in long-chain reasoning. The move from whole-trajectory to critical-step optimization is a significant refinement for reasoning tasks.