📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Chain-of-Thought (CoT) Reasoning
Reasoning performance in RLVR is driven almost entirely by a minority of high-entropy 'forking' tokens that determine reasoning paths, allowing for effective training using only gradients from the top 20% most uncertain tokens.
Core Problem
Current RLVR methods train on all tokens equally, neglecting the heterogeneous functional roles tokens play in reasoning and failing to prioritize critical decision points.
Why it matters:
- Computational inefficiency: Gradient updates are wasted on low-entropy tokens (suffixes, predictable completions) that do not influence reasoning logic.
- Lack of interpretability: We do not fully understand which parts of a Chain-of-Thought trajectory actually drive the improvements seen in modern reasoning models.
- Potential optimization interference: Training on low-entropy tokens might introduce noise or hinder performance, as seen when exclusively training on the bottom 80%.
Concrete Example:
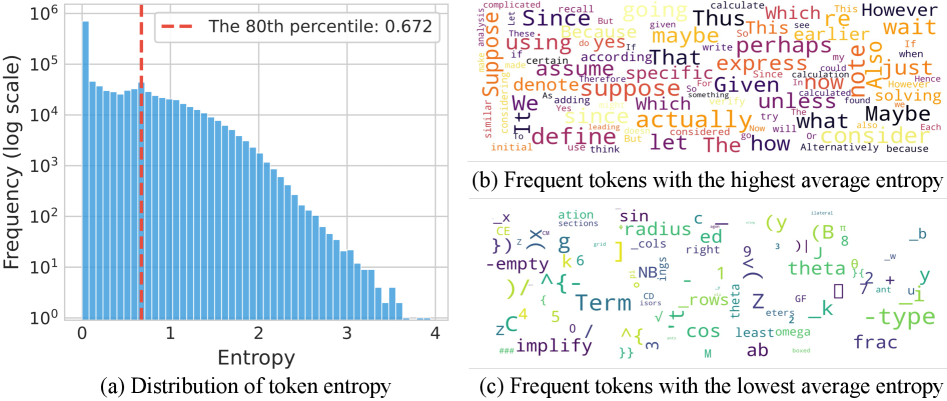
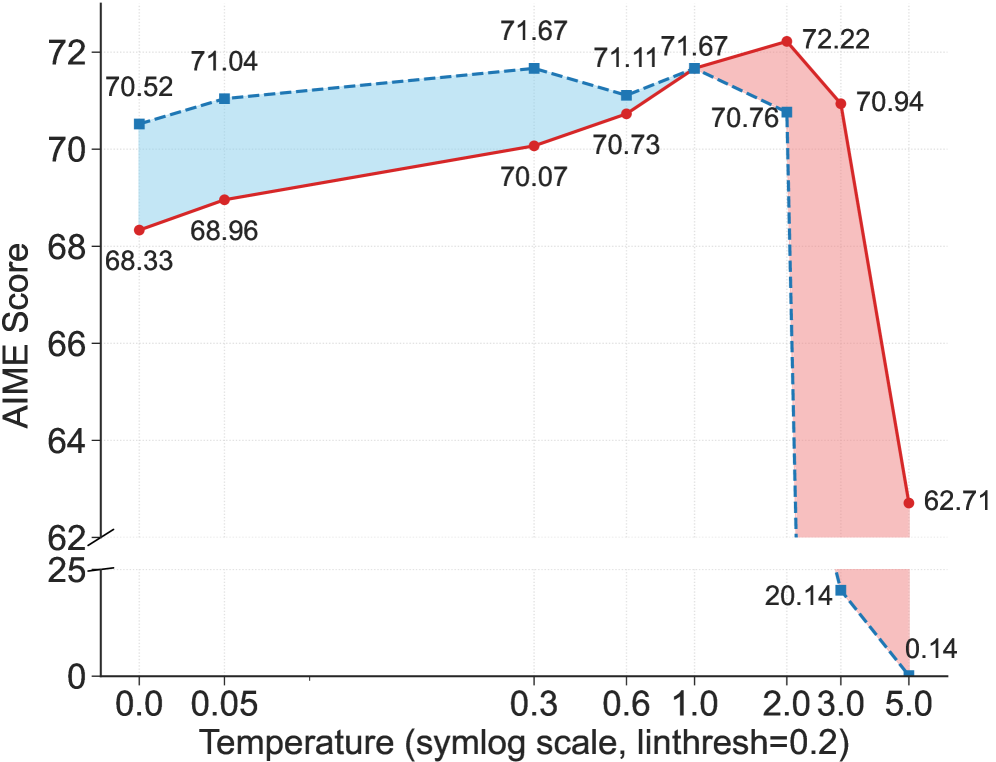
In a mathematical derivation, tokens like 'suppose' or 'thus' (high entropy) steer the logic, while tokens completing a LaTeX formula (low entropy) are deterministic. Standard RLVR treats them the same. The paper shows that artificially lowering the temperature of 'forking' tokens degrades performance, proving their specific importance.
Key Novelty
Entropy-Based Sparse RLVR (Forking Token Optimization)
- Identifies 'forking tokens': A small minority (top ~20%) of tokens in Chain-of-Thought reasoning that have high entropy and act as pivotal decision points.
- Proposes a sparse training strategy: Restricting policy gradient updates exclusively to these high-entropy tokens while masking the remaining 80%.
- Demonstrates that this sparse update method matches or exceeds full-gradient performance, suggesting the '80/20 rule' applies strictly to token contribution in reasoning.
Architecture
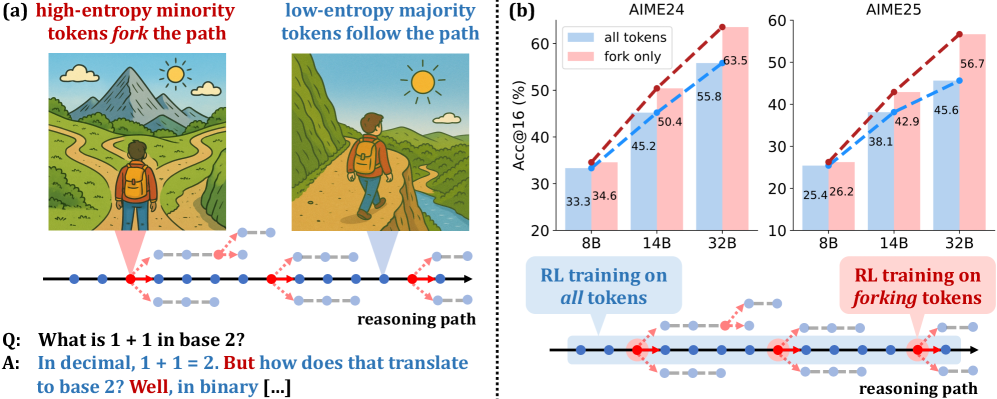
Conceptual illustration of 'Forking Tokens' in a Chain-of-Thought
Evaluation Highlights
- +11.04 accuracy on AIME'25 and +7.71 on AIME'24 for Qwen3-32B using only the top 20% high-entropy tokens compared to the base model.
- The 32B model trained on sparse tokens achieves 63.5 on AIME'24 and 56.7 on AIME'25, setting a new SOTA for models under 600B parameters.
- Training exclusively on the bottom 80% lowest-entropy tokens causes severe performance degradation, confirming they contribute little to reasoning improvements.
Breakthrough Assessment
9/10
Reveals a fundamental mechanism of CoT reasoning (forking tokens) and achieves SOTA results with a method that theoretically requires computing gradients for only 20% of tokens.