📝 Paper Summary
Benchmark datasets
Modularized RAG pipeline
CRAG is a diverse factual QA benchmark for RAG systems featuring 4,409 questions with mock APIs and full HTML pages, revealing that even state-of-the-art RAG solutions struggle with dynamic, long-tail, and complex queries.
Core Problem
Existing RAG benchmarks (like NQ or MS MARCO) rely on static, text-only snippets and fail to represent the diverse, dynamic nature of real-world QA (e.g., varying popularity, temporal changes, and complex reasoning).
Why it matters:
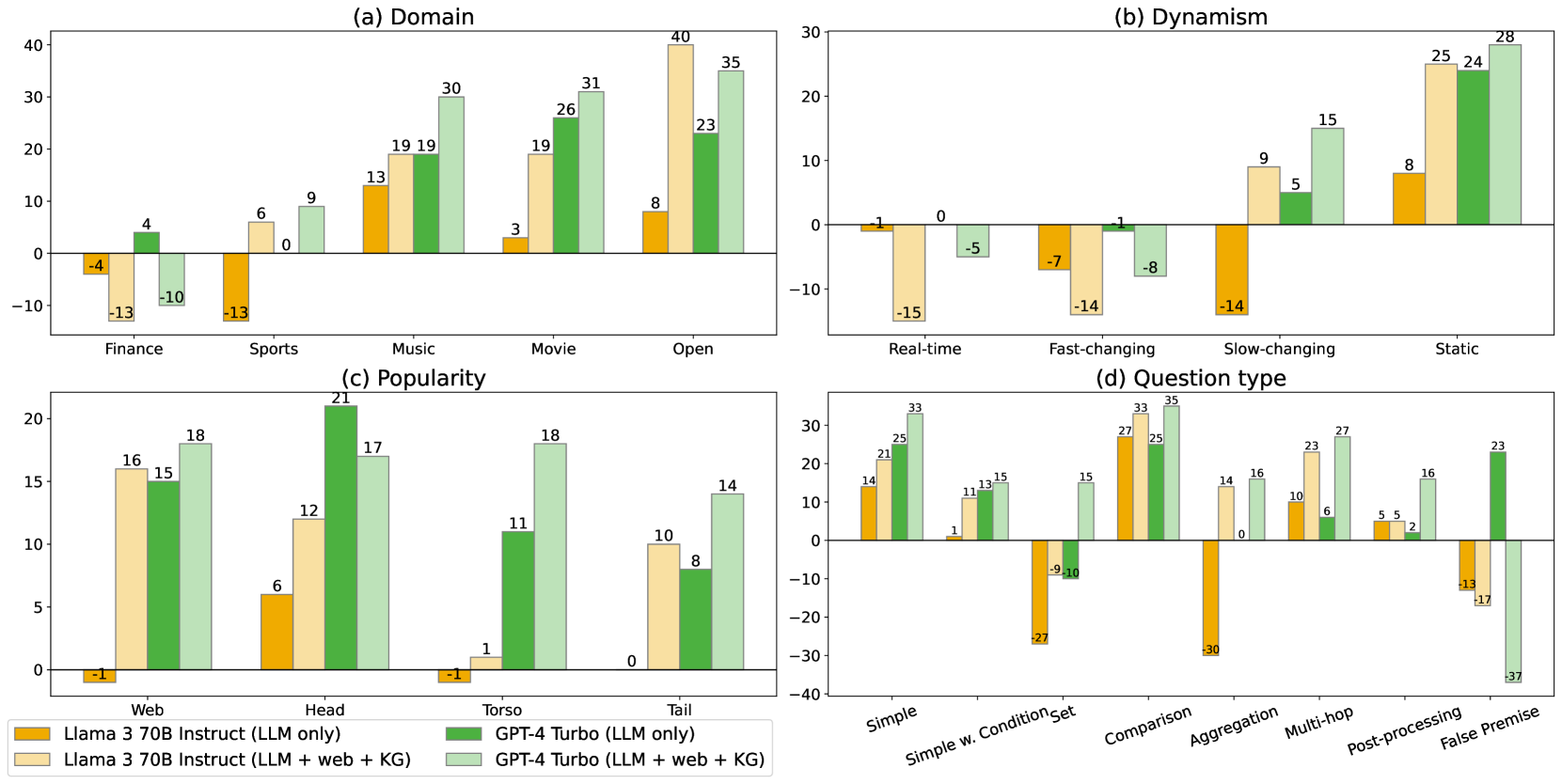
- Current LLMs achieve <35% accuracy on less popular (torso-to-tail) facts, and hallucinations remain a critical barrier to trustworthy systems
- Standard metrics like ROUGE/F1 are insufficient for free-form generation; a reliable, fine-grained evaluation of truthfulness is missing
- Real-world RAG systems must handle structured data (KGs), full HTML parsing, and time-sensitive information, which traditional static benchmarks ignore
Concrete Example:
A question asking for 'most popular action movies in 2023' requires aggregating recent data. An LLM might hallucinate based on outdated training data, while a naive RAG system might fail to parse the structured list from a retrieved HTML page or mock API.
Key Novelty
Comprehensive RAG Benchmark (CRAG) with Mock Environments
- Introduces a dataset of 4,409 QA pairs covering 5 domains (Finance, Sports, etc.) and 8 question types (including complex ones like aggregation and false-premise)
- Provides a realistic retrieval environment including mock Knowledge Graph (KG) APIs and up to 50 full HTML pages per question, simulating real-world search noise
- Implements a scoring system that penalizes hallucinations more severely than 'I don't know' answers to prioritize trustworthiness
Architecture
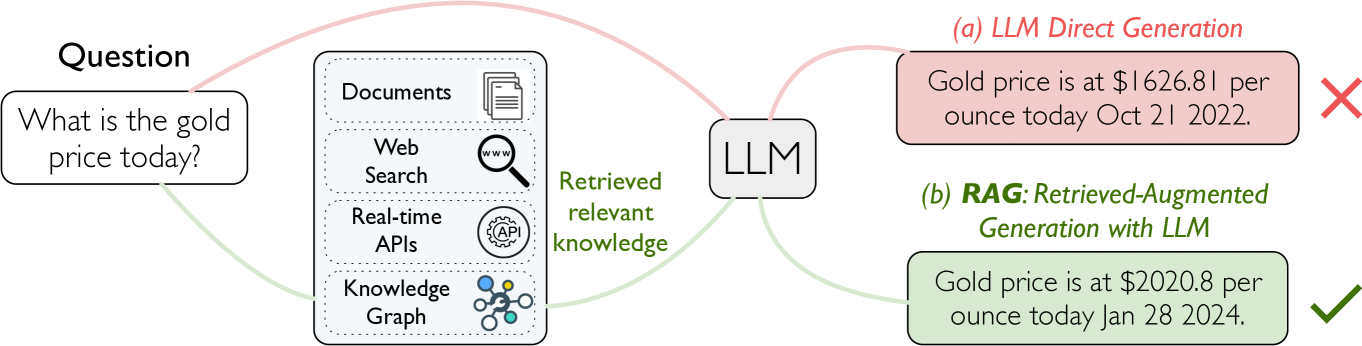
Illustration of a RAG system workflow interacting with the CRAG benchmark
Evaluation Highlights
- State-of-the-art industry RAG solutions achieve only 63% truthfulness (answering without hallucination), highlighting significant reliability gaps
- Basic RAG improves LLM accuracy from ≤34% to 44%, but often introduces more hallucinations due to distraction by retrieval noise
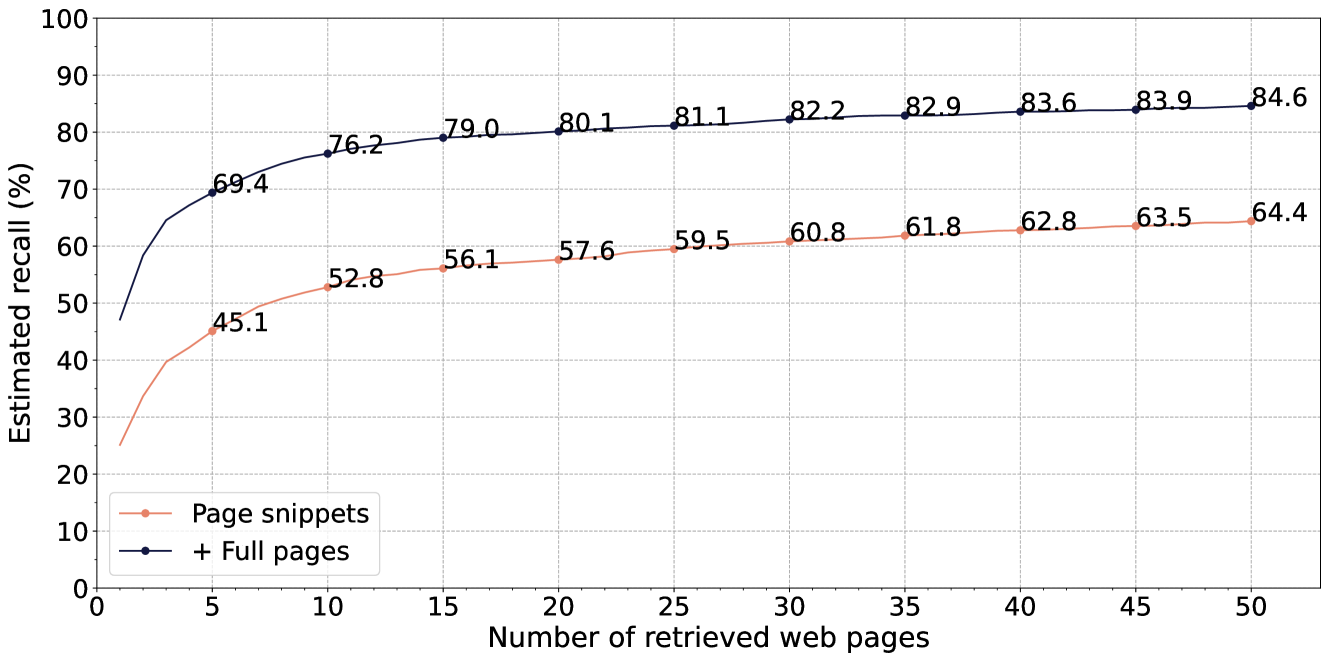
- Web search recall drops significantly for Knowledge Graph questions (74%) compared to Web questions (93%), validating the need for hybrid Web+KG retrieval
Breakthrough Assessment
9/10
A major step forward for RAG evaluation. It moves beyond simple Wikipedia retrieval to include mock APIs, full HTML, and temporal dynamics, setting a new standard for realism in QA benchmarks.