📝 Paper Summary
Memory recall
Dense memory QA
Pensieve is an end-to-end system for answering recall questions about personal multimodal memories by enriching memory snapshots with text descriptions and using time/location-aware retrieval.
Core Problem
Existing Multimodal RAG approaches struggle with personal memory questions because they fail to leverage vague temporal/spatial anchors (e.g., 'yesterday', 'at Macy's') and cannot effectively aggregate information across multiple memory snapshots due to limited visual context windows.
Why it matters:
- Enables smart assistants to function as a 'Second Brain' by recalling specific life events like parking locations or shopping items.
- Current VLMs have limited context windows, making it difficult to reason over large sets of raw image memories directly.
- Recall questions differ from standard visual QA by focusing on tracking objects and events over time rather than simple visual recognition.
Concrete Example:
For a question like 'Where did I park?', a standard system might retrieve irrelevant cars seen recently. Pensieve retrieves the most recent parking memory by combining the visual snapshot with a 'last time' recency score and completes the invocation command 'remember this' with 'remember I parked at slot 142'.
Key Novelty
Pensieve: Task-Oriented Memory Augmentation and Retrieval
- Augments raw memory images offline with rich text metadata (OCR, LLM-generated captions, and invocation command completions) to enable purely text-based reasoning later.
- Employs a 'multi-signal retriever' that explicitly calculates scores for time recency, date matching, and location matching alongside semantic similarity.
- Uses 'noise-injected training' for the answer generator to teach the model to ignore irrelevant retrieved memories.
Architecture
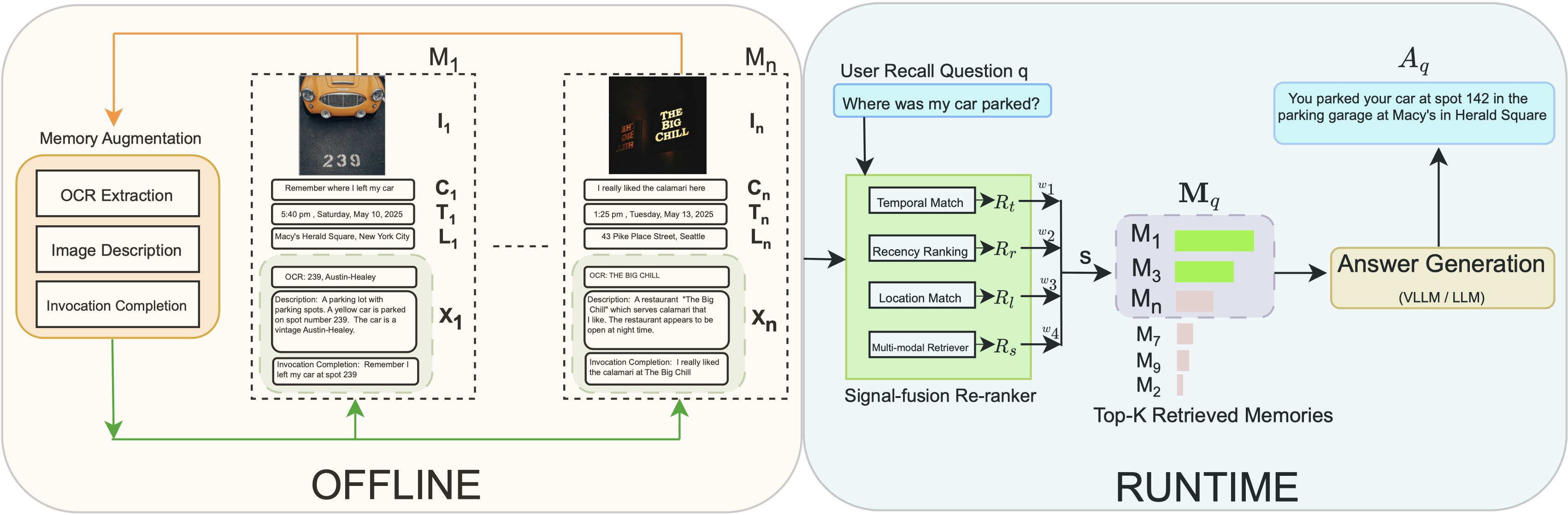
The end-to-end Pensieve pipeline, split into offline augmentation and runtime QA.
Evaluation Highlights
- Improves QA accuracy by up to 14% over state-of-the-art MM-RAG solutions on the MemoryQA benchmark.
- Achieves comparable performance using text-based LLMs on augmented memories as expensive VLMs using raw images.
- Demonstrates robust handling of vague temporal queries (e.g., 'last week') through specialized date parsing and scoring.
Breakthrough Assessment
7/10
Significant practical advance in personal memory systems by effectively combining classic information retrieval signals (time/location) with modern multimodal LLMs. The reliance on offline text augmentation to bypass VLM context limits is a smart engineering choice.