📝 Paper Summary
Visual Question Answering (VQA)
Multi-modal RAG (MM-RAG)
Wearable AI
CRAG-MM is a large-scale multi-modal benchmark specifically designed for wearable AI, featuring egocentric images, multi-turn conversations, and realistic retrieval challenges to evaluate MM-RAG systems.
Core Problem
Existing VQA benchmarks rely on high-quality images and common knowledge, failing to capture the low-quality egocentric imagery and dynamic, factual information needs of modern wearable AI users.
Why it matters:
- Wearable devices like smart glasses capture egocentric images that are often blurred, occluded, or poorly lit, unlike standard VQA datasets
- Users ask factual questions (prices, history) that cannot be answered from images alone, requiring robust external retrieval
- Current benchmarks lack multi-turn conversations with domain shifts, which are essential for natural human-AI interaction
Concrete Example:
A user wearing smart glasses asks 'What is the price of this sofa on Amazon?' while looking at a sofa. Without RAG, a model hallucinates a price. With RAG, it must retrieve correct info despite the image potentially being blurry or the sofa being partially occluded.
Key Novelty
Realistic Wearable MM-RAG Benchmark
- Incorporates 7.9K images with 79% being egocentric (first-person view), deliberately including low-quality captures (blur, low-light) to mimic real wearable hardware constraints
- Provides 2K multi-turn conversations where ~38% involve domain shifts, simulating natural topic drift in user dialogue
- Includes a realistic mock retrieval environment with both Image-KG APIs (structured data) and Web Search APIs (800K webpages) containing noise to test system robustness
Architecture
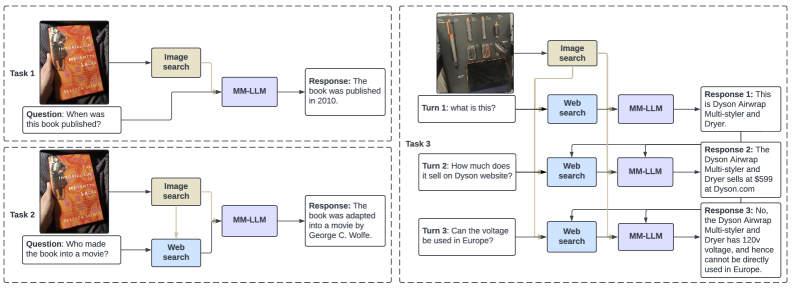
The three tasks defined in CRAG-MM and the flow of information for each. It illustrates the different retrieval sources available for each task.
Evaluation Highlights
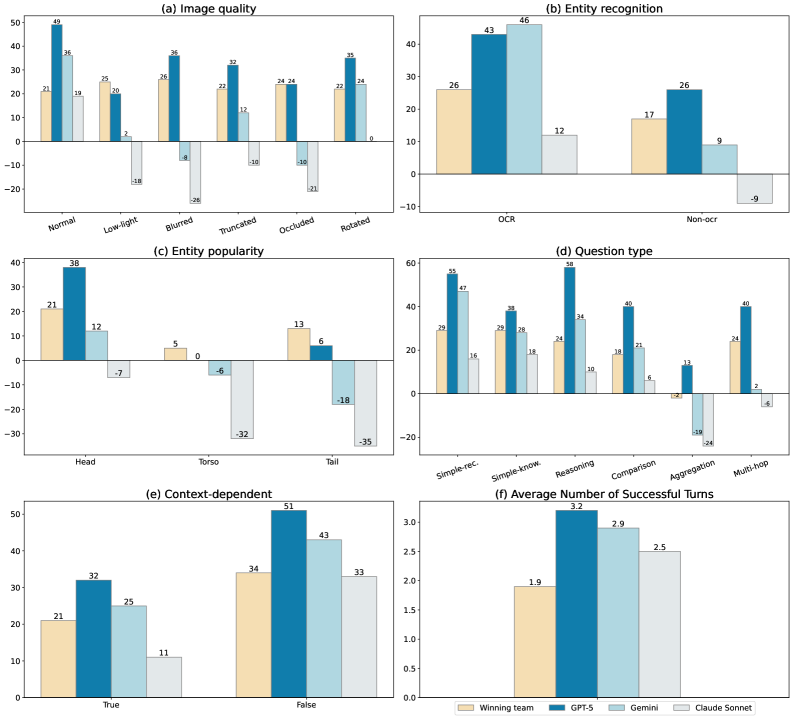
- State-of-the-art industry solution (GPT-5) achieves only 63% accuracy with 31% hallucinations on single-turn QA, underscoring significant room for improvement
- Low-quality egocentric images degrade truthfulness by up to 46% compared to normal images across evaluated systems
- Straightforward RAG approaches improve accuracy over MM-LLM-only baselines (37% to 50%) but still fall short of industry solutions (63%)
Breakthrough Assessment
9/10
First comprehensive benchmark for Multi-Modal RAG specifically targeting wearable use cases. The inclusion of egocentric, low-quality images and multi-turn retrieval tasks fills a critical gap in VQA evaluation.