📝 Paper Summary
Modularized RAG pipeline
Graph-based RAG pipeline
KERAG improves Knowledge Graph Question Answering by retrieving broader entity-level neighborhoods instead of rigid paths, then using a fine-tuned Chain-of-Thought LLM to filter and summarize the answer.
Core Problem
Traditional Semantic Parsing (SP) for KGQA retrieves only strictly necessary triples, leading to low coverage (high miss rates) due to rigid schemas and parsing errors.
Why it matters:
- Rigid SP-based methods fail when natural language questions are ambiguous or do not perfectly match the KG schema.
- Existing LLM-based KGQA methods that generate retrieval paths still suffer from low recall (missing answers) because they only explore a few specific paths rather than the broader context.
- Head entities in KGs have massive neighborhoods (up to 2M triples), creating noise that overwhelms standard RAG summarizers.
Concrete Example:
For the query 'Which books written by J.K. Rowling are related to magic?', a standard SP approach generates a SPARQL query looking for a specific `:topic :Magic` triple. If the KG records 'magic' in the `:description` attribute instead of `:topic`, the query returns empty results. KERAG retrieves the entire 'J.K. Rowling' neighborhood and uses an LLM to find 'magic' within the descriptions.
Key Novelty
Retrieval-Filter-Summarization over Entity Neighborhoods
- Shifts from triple-level retrieval (finding exact paths) to entity-level retrieval (gathering broad subgraphs around topic entities) to maximize recall.
- Interleaves multi-hop retrieval with schema-based filtering during planning to manage the volume of data without overwhelming the context window.
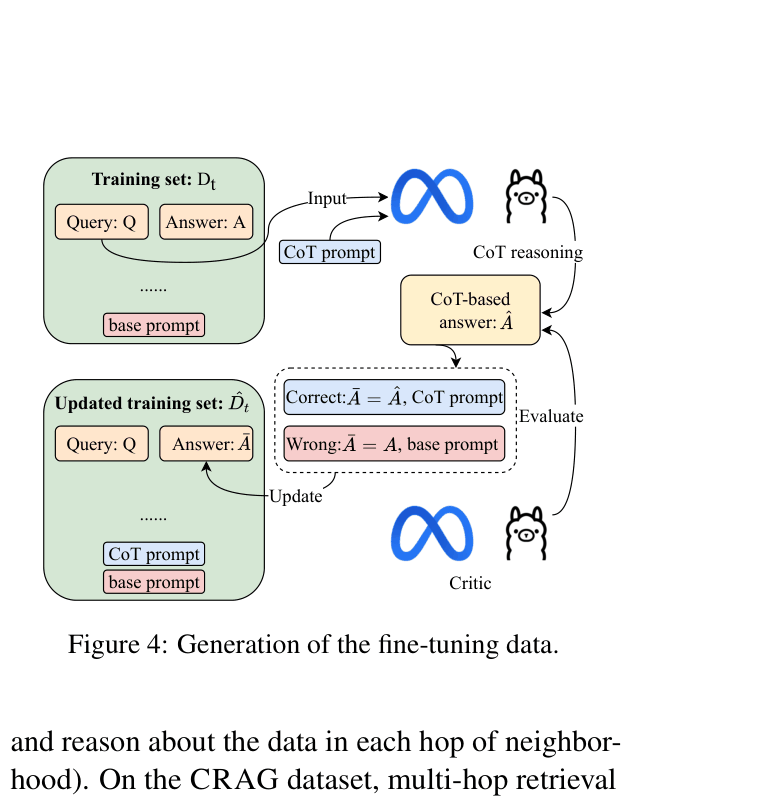
- Uses a fine-tuned Chain-of-Thought (CoT) summarizer trained on synthetic data (generated by validating LLM reasoning against ground truth) to handle complex aggregation and reasoning.
Architecture
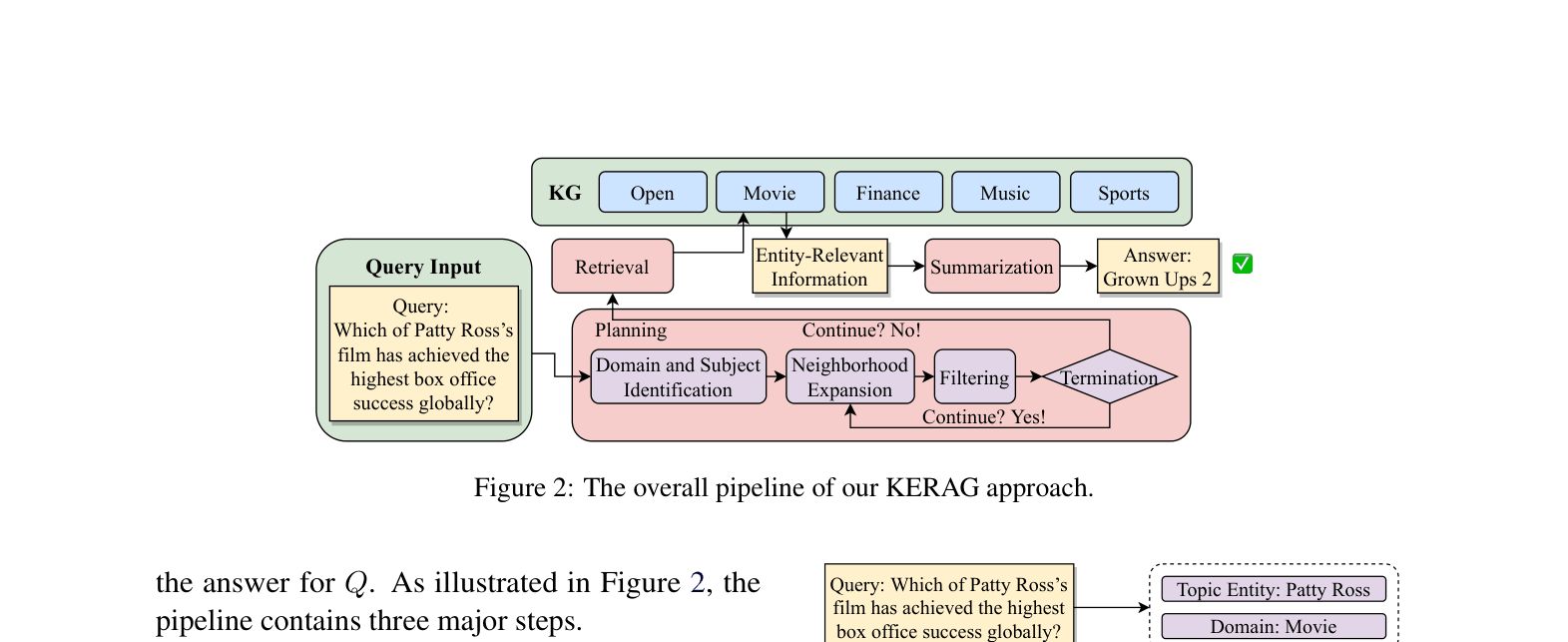
The overall pipeline of KERAG involving Planning, Retrieval, and Summarization.
Evaluation Highlights
- Outperforms state-of-the-art KGQA methods (WikiSP, StructGPT, ToG) by ~7-8% in truthfulness on the Head2Tail benchmark.
- Surpasses GPT-4o (Tool-use) by 21.4% in truthfulness on the CRAG benchmark (0.529 vs 0.315), primarily by reducing the miss rate from 59% to 6.6%.
- Achieves 90.8% accuracy on Head2Tail, effectively solving simple KGQA questions while maintaining robustness across head, torso, and tail entities.
Breakthrough Assessment
8/10
Significant improvement in KGQA recall/coverage by abandoning rigid semantic parsing for broad neighborhood retrieval. The fine-tuning strategy for CoT summarization is practical and effective.