📝 Paper Summary
Modularized RAG pipeline
RAG triggering
Hallucination suppression
ConfQA fine-tunes LLMs on atomic facts with a dampening prompt to recognize their own ignorance, enabling ConfRAG to trigger retrieval only when the model admits uncertainty.
Core Problem
LLMs often hallucinate facts and systematically overestimate their own confidence, making self-reported confidence unreliable for deciding when to trigger expensive RAG processes.
Why it matters:
- Current RAG triggering strategies are either too coarse (trigger for all questions) or rely on complex internal signals (token entropy) that are hard to calibrate
- Self-reported confidence in standard LLMs is often over-confident; models will confidently state incorrect facts rather than admitting ignorance
- Running RAG for every query incurs unnecessary latency and computation costs when the model already knows the answer
Concrete Example:
When answering a static factual question about a 'torso-to-tail' popularity entity, a standard Llama-3.1-70B might report 80% confidence but only achieve 33% actual accuracy (as seen in CRAG benchmarks), leading to hallucinations instead of retrieval.
Key Novelty
ConfQA (Calibration Fine-tuning) & ConfRAG (Uncertainty-Based Triggering)
- Teaches the model to say 'I am unsure' for incorrect internal knowledge by fine-tuning on atomic facts (DBPedia attributes) where the model's unprompted answer is compared to ground truth
- Uses a 'dampener prompt' ('Answer only if you are confident') during both training and inference to explicitly suppress overconfident hallucinations
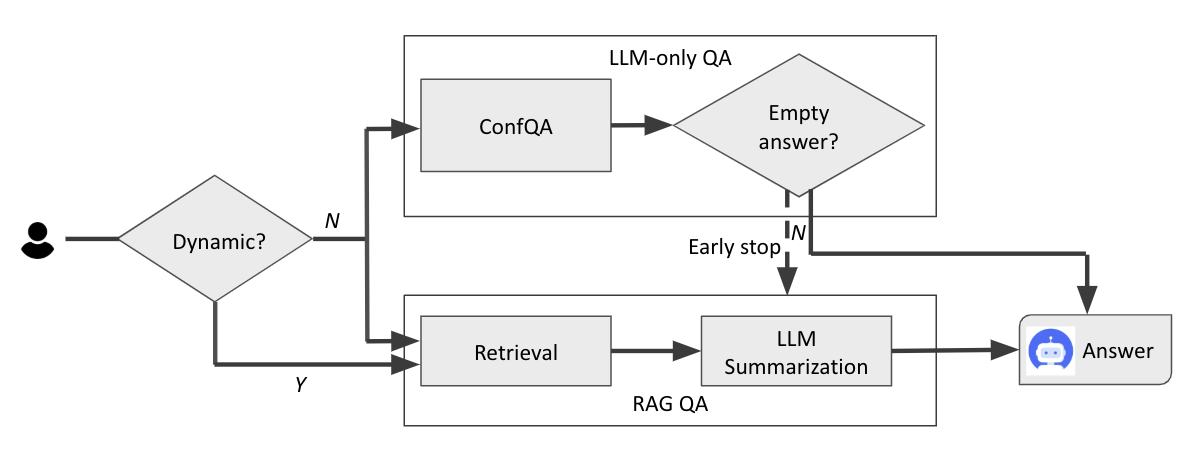
- Triggers RAG only when the fine-tuned model outputs the specific token sequence 'I am unsure', running generation and retrieval in parallel but early-stopping RAG if the model is confident
Architecture
The ConfRAG inference pipeline illustrating parallel execution of LLM and RAG.
Evaluation Highlights
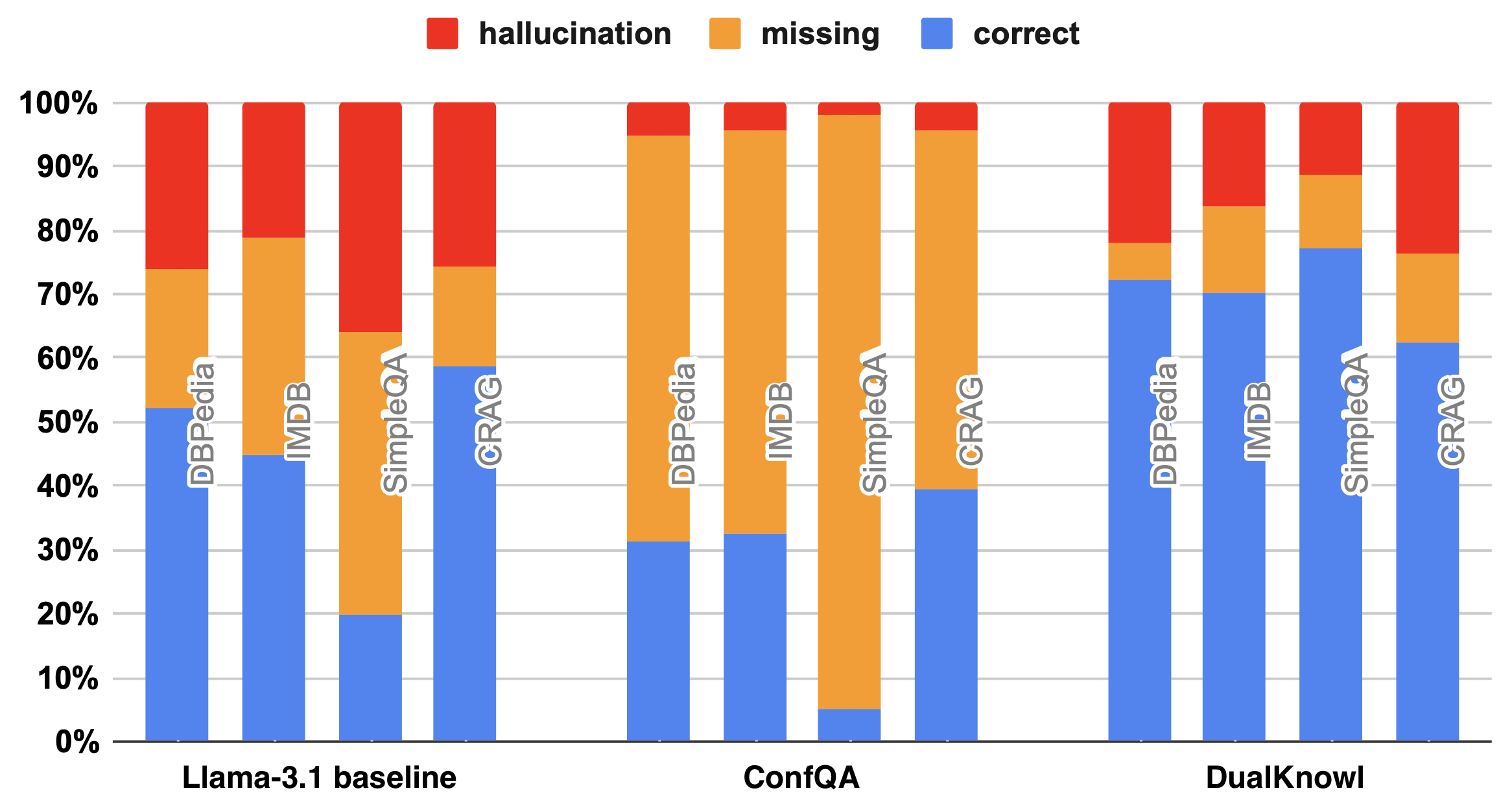
- ConfQA reduces hallucination rates from 20–40% to below 5% across multiple short-form factuality benchmarks (SimpleQA, CRAG, DBPedia)
- ConfRAG reduces unnecessary external retrievals by over 30% compared to always-on RAG while maintaining >95% accuracy (theoretical ideal)
- Reduces P50 latency by over 600ms on the CRAG benchmark compared to always invoking RAG
Breakthrough Assessment
8/10
Strong practical contribution. Successfully solves the 'overconfidence' problem for RAG triggering using a simple but highly effective fine-tuning recipe (atomic facts + dampener prompt). Significant latency/cost reductions.