📝 Paper Summary
Hallucination suppression
Reinforcement Learning from Human Feedback (RLHF)
TruthRL optimizes LLM truthfulness using reinforcement learning with a ternary reward system that explicitly incentivizes abstention over hallucination while rewarding correctness.
Core Problem
Existing methods optimize for accuracy, which incentivizes guessing and hallucinations when the model lacks knowledge, or use conservative fine-tuning that causes excessive abstention.
Why it matters:
- In high-stakes domains (law, medicine), confident hallucinations are far more dangerous than admitting ignorance ('I don't know')
- Standard accuracy-driven objectives (SFT, binary RL) implicitly favor guessing because the expected reward for a lucky guess is higher than abstaining
- Current methods struggle to balance the trade-off between answering correctly and recognizing knowledge boundaries, often swinging to extremes of fabrication or silence
Concrete Example:
On the CRAG benchmark, vanilla SFT models achieve high accuracy but rarely abstain (near 0% uncertainty rate), leading to high hallucination on difficult questions. Conversely, R-Tuning requires complex data annotation and can become overly conservative.
Key Novelty
Truthfulness-Driven Ternary Reward Optimization
- Introduces a ternary reward structure (+1 for correct, 0 for abstention, -1 for hallucination) that makes abstaining mathematically preferable to guessing when confidence is low
- Uses GRPO (Group Relative Policy Optimization) to apply this reward, allowing the model to learn the relative advantage of admitting ignorance over risking a hallucination
- Optimizes a composite 'Truthfulness' metric rather than raw accuracy, explicitly balancing correctness, uncertainty (abstention), and hallucination reduction
Architecture

Comparison of Accuracy-Driven vs. Truthfulness-Driven objectives. It illustrates how binary rewards (Accuracy) push models to guess, whereas ternary rewards (Truthfulness) create a safe 'Abstain' zone.
Evaluation Highlights
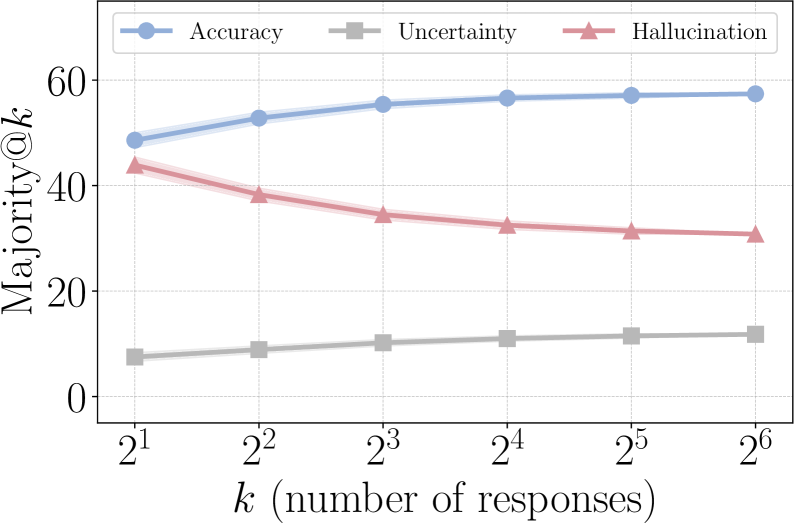
- Reduces hallucination rate by 28.9% and improves truthfulness score by 21.1% compared to vanilla RL on knowledge-intensive benchmarks
- On challenging CRAG subsets where baselines hallucinate nearly 100% of the time, TruthRL abstains 84.5% of the time with only 15.5% hallucinations
- Outperforms both vanilla SFT and knowledge-enhanced baselines (RFT, R-Tuning) across Llama-3.1-8B and Qwen-2.5-7B models in both retrieval and non-retrieval settings
Breakthrough Assessment
8/10
Provides a principled, simple solution (ternary rewards) to a critical safety problem (hallucination) that outperforms complex alternatives. The shift from accuracy-driven to truthfulness-driven RL is a significant conceptual improvement.