📝 Paper Summary
Temporal Knowledge Graph Question Answering (TKGQA)
Retrieval-Augmented Generation (RAG)
PoK improves temporal question answering by decomposing complex queries into structured sub-objectives (Retrieve, Rank, Reason) and retrieving facts using a contrastive time-aware embedding model.
Core Problem
LLMs struggle with complex multi-hop temporal reasoning, often suffering from hallucinations due to implicit temporal constraints and a lack of specific temporal knowledge.
Why it matters:
- Standard RAG methods prioritize semantic similarity but overlook temporal consistency (e.g., retrieving facts from the wrong year)
- Path-based reasoning on Temporal Knowledge Graphs is computationally complex and often fails to find valid paths for multi-hop queries
- LLMs frequently generate factually incorrect timelines or confuse temporal order (e.g., 'before' vs. 'after') when reasoning implicitly
Concrete Example:
For the question 'After the Danish Ministry, who was the first to visit Iraq?', standard Chain-of-Thought might hallucinate a visit date or person. Text-based RAG might retrieve a visit from 2016 when the question implies a sequence starting in 2003, failing to respect the 'after' constraint.
Key Novelty
Plan of Knowledge (PoK) Framework
- Decomposes questions into executable sub-objectives using three specific operators: Retrieve (fetch facts), Rank (sort chronologically), and Reason (infer answer)
- Constructs a Temporal Knowledge Store (TKS) where facts are encoded as text with time-aware contrastive learning to align questions with temporally relevant facts
Architecture
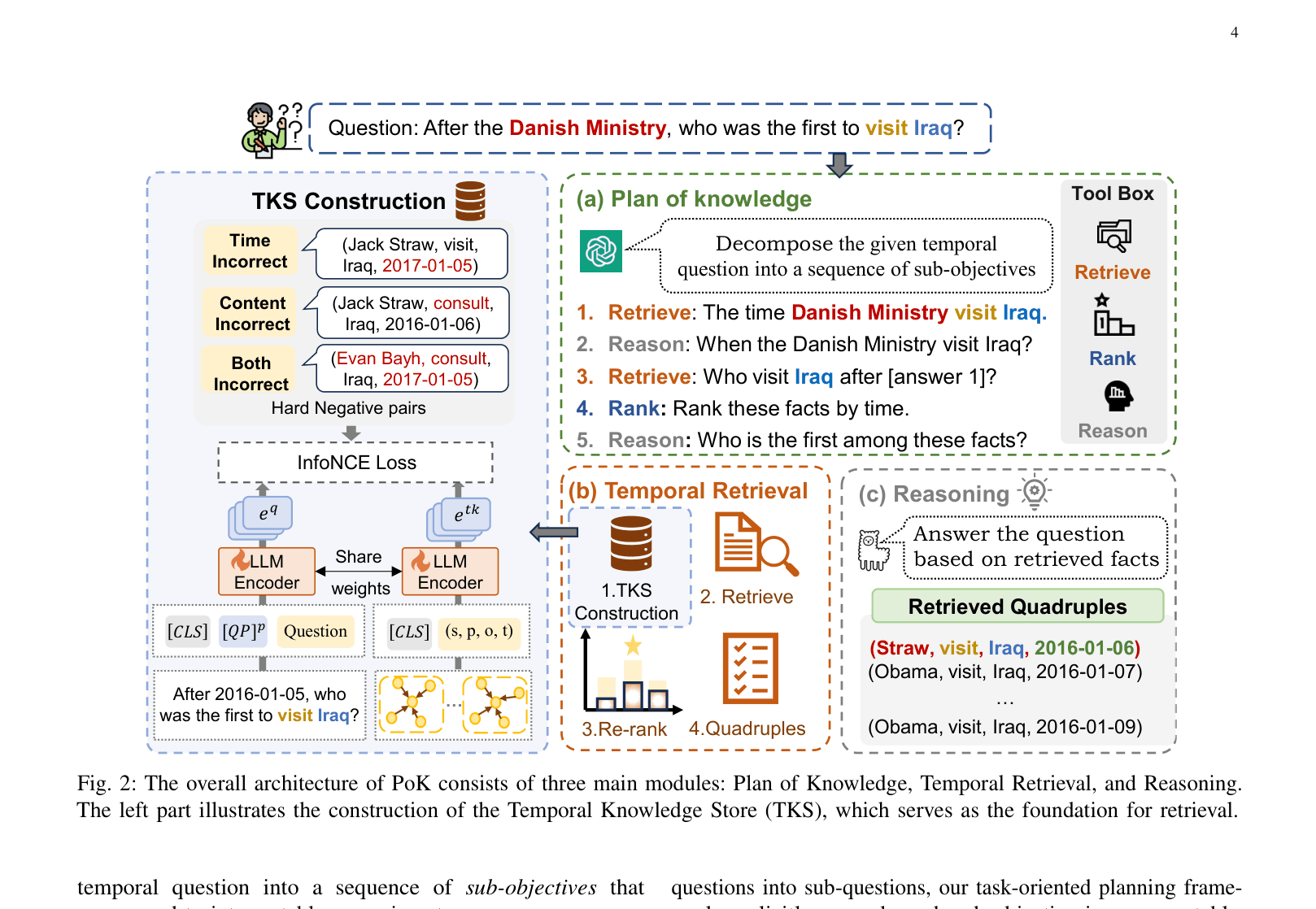
The overall architecture of the PoK framework, detailing the pipeline from question input to answer generation.
Evaluation Highlights
- Achieves 77.9% Hits@1 on the MultiTQ dataset, outperforming the previous state-of-the-art RTQA by 1.8%
- Surpasses GenTKGQA on the TimeQuestions dataset with 83.2% Hits@1 compared to 58.4%
- Demonstrates massive gains on complex questions in Timeline-ICEWS, improving Hits@1 from 37.6% (GPT-4o) to 68.3%
Breakthrough Assessment
7/10
Strong empirical results (+56% on some benchmarks) and a logical decomposition framework. The approach effectively bridges structured KG reasoning and LLM generation, though it relies on standard components (LLaMA/Qwen) arranged novelly.