📝 Paper Summary
Task-Oriented Dialogue (TOD)
Agentic Memory Systems
Agentic Benchmarking
ATOD introduces a benchmark and memory-based evaluation framework designed to assess agentic dialogue systems on complex tasks involving interleaved goals, long-horizon memory, and asynchronous execution.
Core Problem
Existing task-oriented dialogue benchmarks focus on sequential, single-goal interactions and fail to evaluate advanced agentic capabilities like managing concurrent goals, handling delays, or recalling context across long horizons.
Why it matters:
- Modern users expect agents to handle interleaved workflows (e.g., pausing a booking to check a payment) rather than rigid turn-by-turn sequences
- Current metrics (Inform/Success rate) treat all goals equally, penalizing agents for blocked goals that cannot yet be completed due to dependencies
- Lack of standardized protocols for evaluating persistent memory across sessions limits progress in building truly helpful, long-term companions
Concrete Example:
In a travel scenario, a user might request a flight booking but need to check a visa requirement first. Traditional systems fail if the flight goal is 'incomplete' at the end, even if the agent correctly paused it to wait for the visa check. ATOD evaluates this dependency correctly.
Key Novelty
ATOD (Agentic Task-Oriented Dialogue) Benchmark & Evaluator
- Generates synthetic dialogues using a 'goal co-occurrence graph' to simulate realistic, multi-goal, and interleaved user behaviors rather than random sampling
- Proposes a 'Dependency-Aware Goal Completion Rate' metric that only penalizes uncompleted goals if their prerequisites were actually met
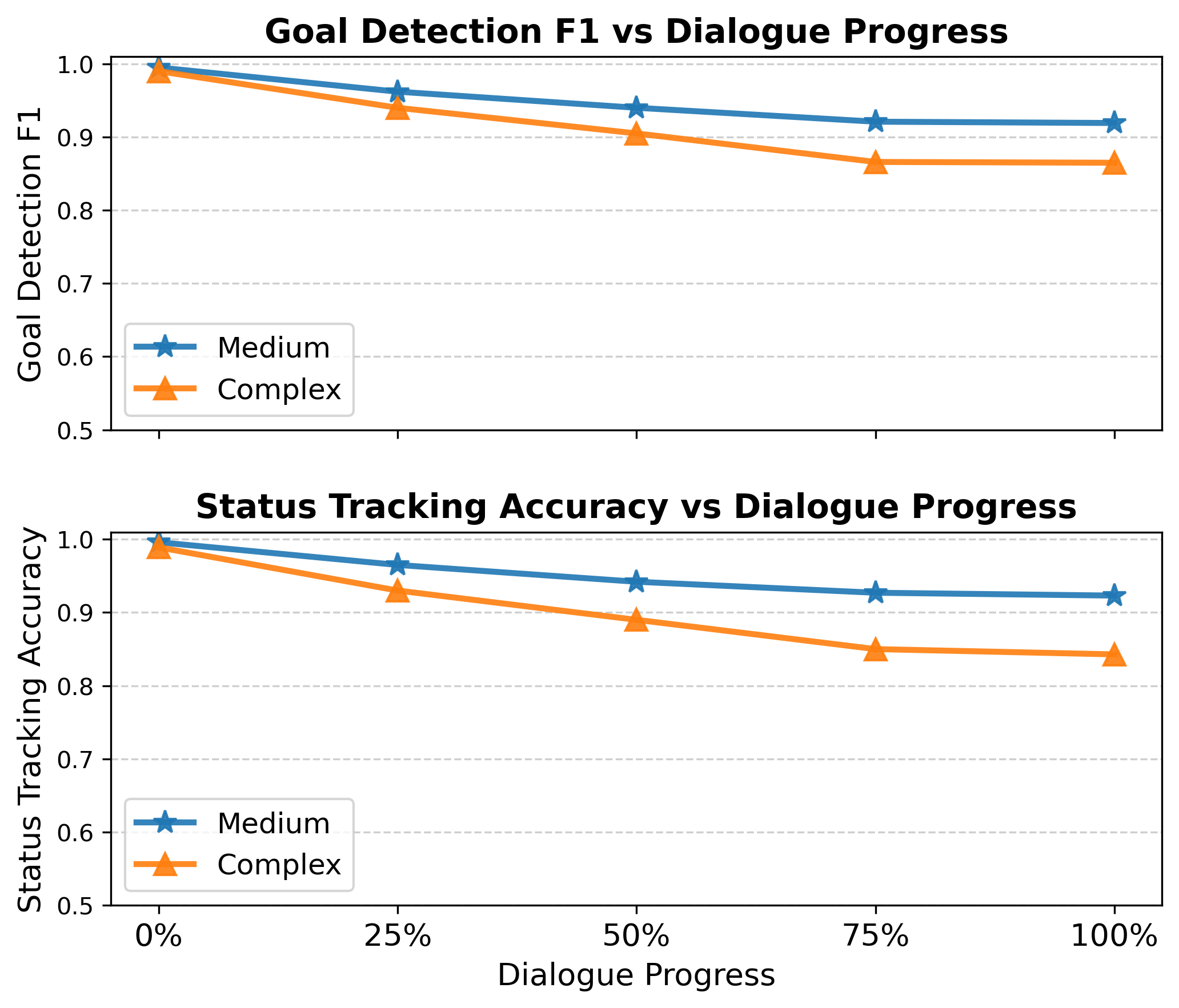
- Introduces a dual-store agentic memory evaluator (symbolic database + vector store) that tracks goal states (Open/Pending/Blocked) turn-by-turn, offering more accuracy than zero-shot LLM judges
Architecture
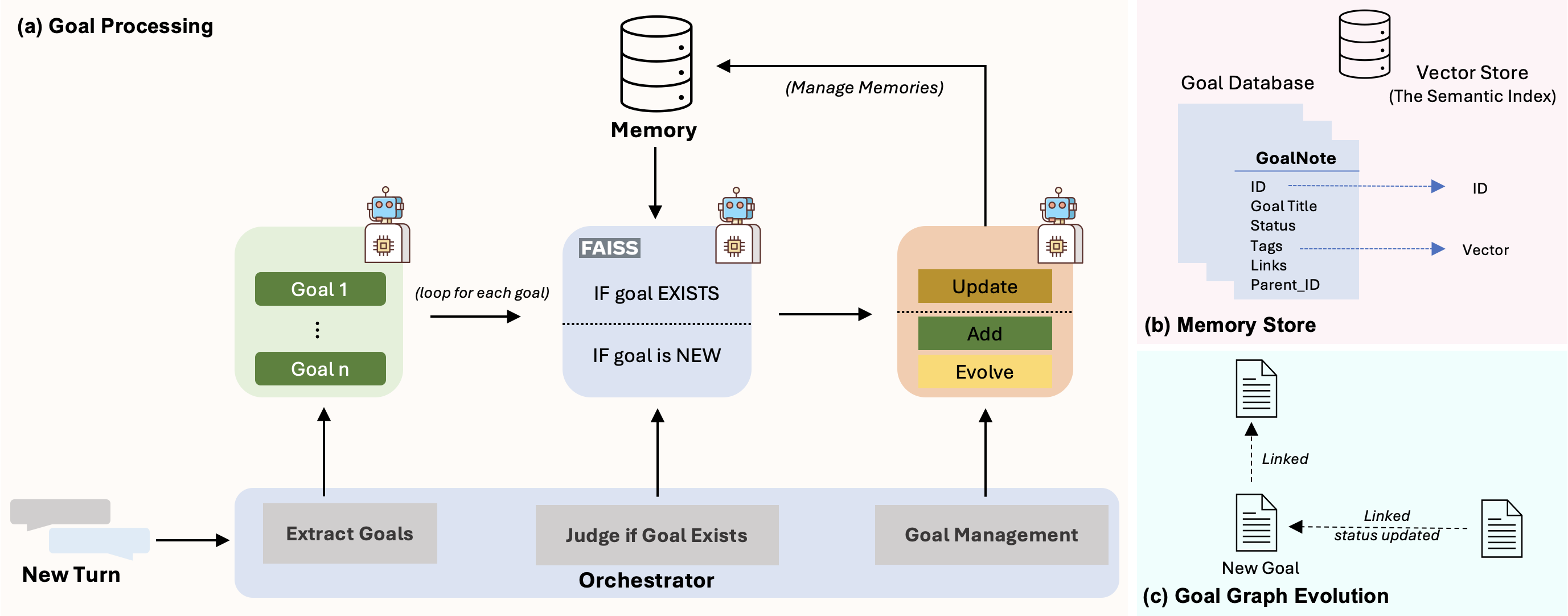
The ATOD-Eval Agentic Memory System architecture and processing pipeline.
Evaluation Highlights
- The proposed memory-based evaluator achieves ~25-30% higher Goal Detection Accuracy than Claude-3.5-Sonnet and GPT-4 based judges in complex dialogue settings
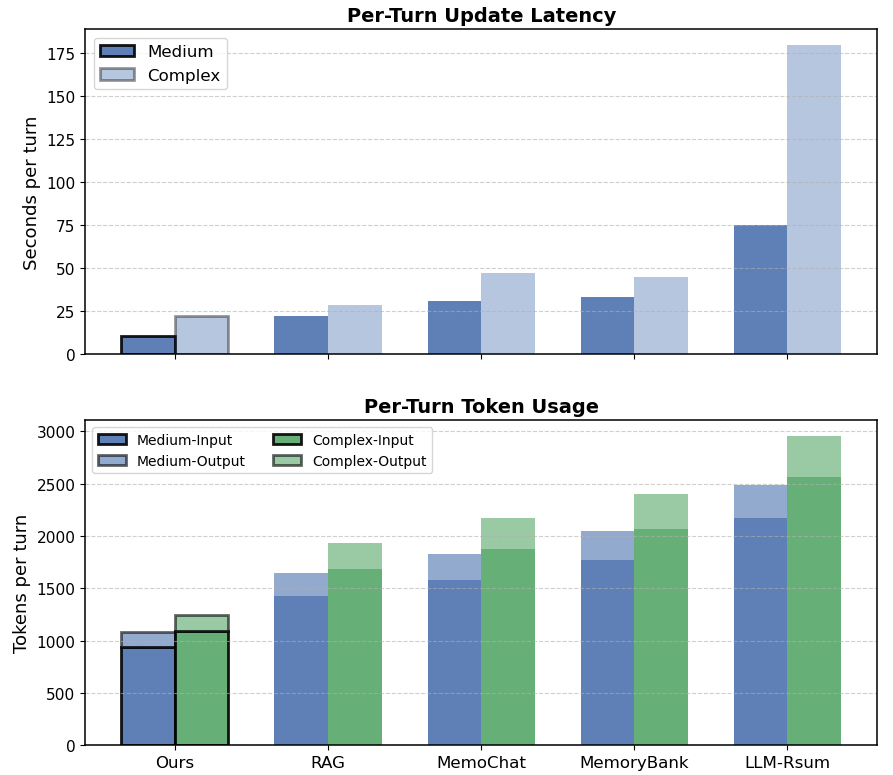
- Reduces evaluation latency significantly: <25 seconds per turn compared to >180 seconds for baseline memory approaches like LLM-Rsum
- Demonstrates high stability in state tracking, maintaining near-perfect accuracy at early dialogue stages and degrading gracefully compared to baselines as context length grows
Breakthrough Assessment
8/10
Addresses a critical gap in TOD evaluation by formalizing 'advanced' behaviors (interleaving, dependencies). The shift from success-rate to dependency-aware metrics is a necessary evolution for agentic AI.