📝 Paper Summary
Modularized RAG pipeline
Structure-R1 uses reinforcement learning to train a language model to transform retrieved unstructured text into adaptive structured formats (like tables or graphs) that maximize reasoning accuracy.
Core Problem
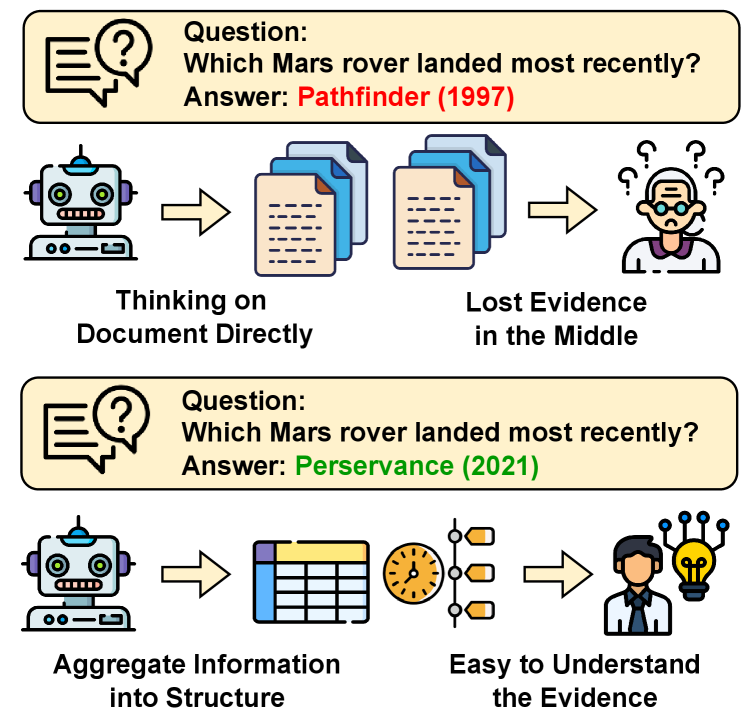
Traditional RAG systems feed fragmented, unstructured text chunks to LLMs, resulting in low information density and 'lost in the middle' phenomena where models overlook critical reasoning cues.
Why it matters:
- Standard RAG struggles with complex multi-step reasoning because raw text chunks are often noisy and disorganized.
- Existing structured approaches (like Knowledge Graph RAG) rely on fixed schemas, lacking the flexibility to adapt to diverse query types.
- LLMs often fail to extract reliable structures from documents without explicit verification mechanisms.
Concrete Example:
For the query 'Which Mars rover landed most recently?', a standard RAG retrieves scattered text about various missions. Structure-R1 transforms this into a table mapping missions to dates, then potentially a timeline, making the 'most recent' comparison trivial for the model to solve.
Key Novelty
Generative Structure-Representation Policy with Self-Verification
- Instead of using a fixed retriever or static knowledge graph, the model learns a policy to dynamically convert text into the most useful structure (Table, Graph, Algorithm, etc.) for the specific query.
- Uses a 'self-reward' mechanism during training: the model verifies its own generated structure by attempting to answer the question using *only* the structure (without original docs), ensuring the structure is self-contained.
Architecture
The Structure-R1 inference and training pipeline.
Evaluation Highlights
- Achieves state-of-the-art performance among 7B-scale models across seven knowledge-intensive benchmarks.
- Matches or outperforms significantly larger models like GPT-4o-mini on multiple benchmarks.
- Demonstrates the ability to invent new, non-predefined structural formats when the standard set (tables, graphs, etc.) is insufficient.
Breakthrough Assessment
8/10
Strong conceptual advance by treating 'structuring' as a learnable, dynamic policy rather than a preprocessing step. The self-verification reward is a clever solution to the 'hallucinated structure' problem.