📝 Paper Summary
Modularized RAG pipeline
Retrieval
CoAugRetriever uses reinforcement learning to jointly optimize an LLM that augments both user queries and corpus documents, aligning their semantic representations for better retrieval performance.
Core Problem
Current LLM-based retrieval methods focus only on query rewriting, which is insufficient for challenging corpora where documents themselves are semantically distant from queries or lack sufficient context.
Why it matters:
- Enhancing queries alone hits a bottleneck in challenging knowledge domains where accurately retrieving information from a compact corpus is crucial
- Simply allowing an LLM to modify documents without coordination yields little benefit and can even degrade performance due to misalignment
- Jointly training query and document augmentation is difficult because the reward depends on the interaction of both, creating an intractable action space
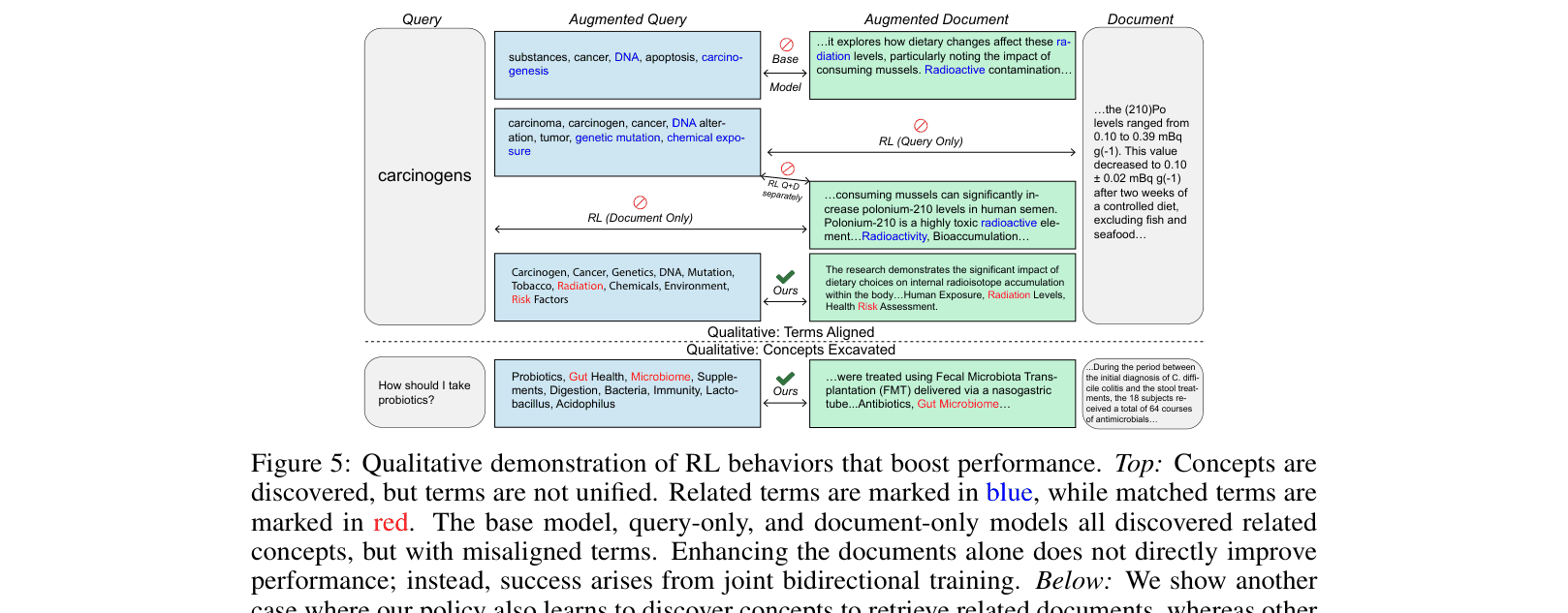
Concrete Example:
For a query 'carcinogens' targeting a document about '(210)Po', standard models generate related but mismatched terms (query: 'DNA', 'genetic mutation'; document: 'radioactivity'). CoAugRetriever aligns them by generating the shared terms 'radiation' and 'risk' in both the query and document expansions, enabling a successful match.
Key Novelty
Bidirectional Reinforcement Learning for Co-Augmentation
- Treats both query augmentation and document augmentation as collaborative policies learned by the same LLM via RL
- Uses a 'composite sampling' strategy that groups queries with relevant/irrelevant documents into a single batch to make joint training computationally feasible
- Introduces a multi-sampling reward estimation that averages retrieval scores across different rollout combinations to handle the large joint action space
Architecture
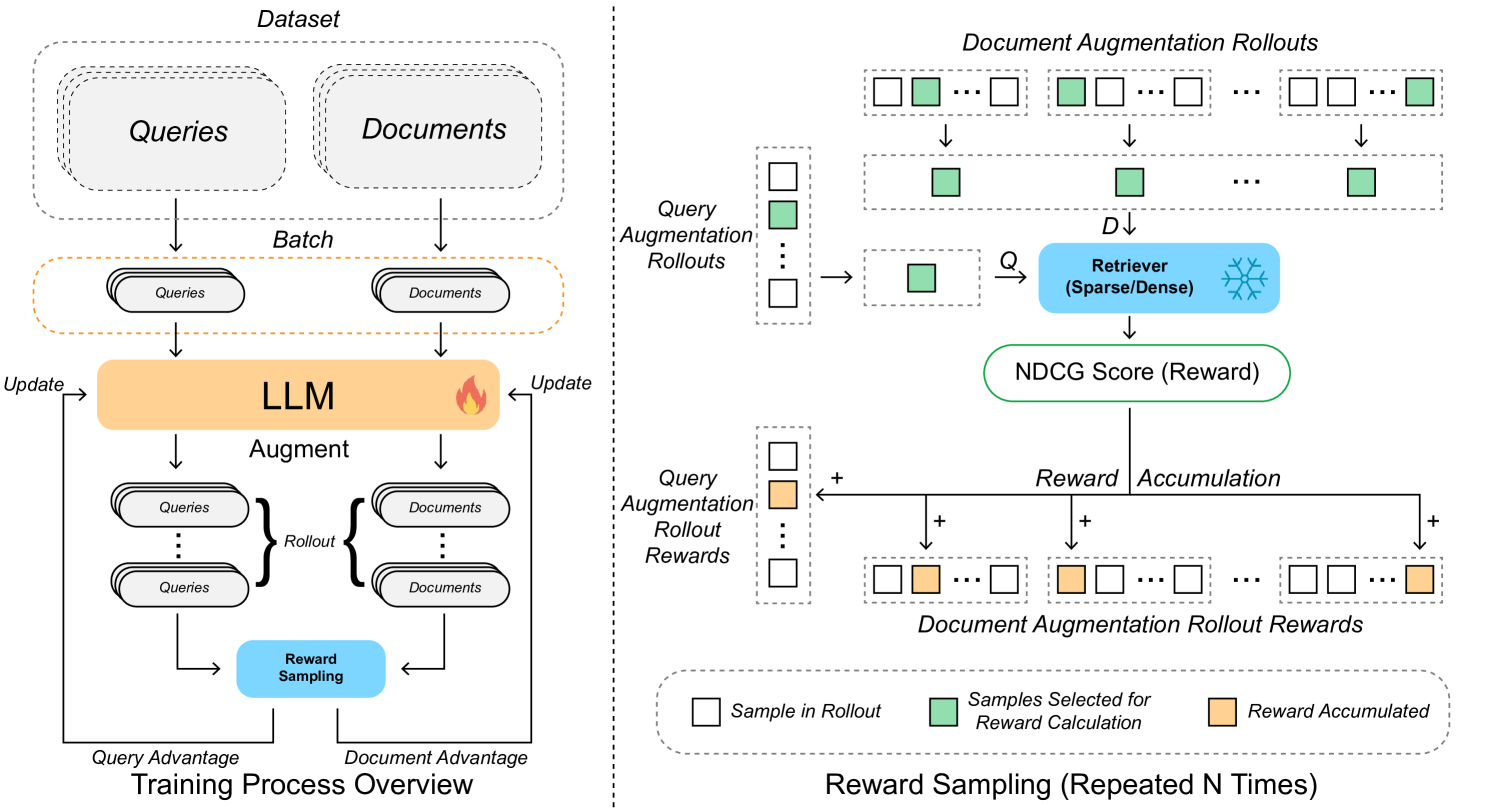
The training pipeline showing Batch Sampling, Rollout generation for both queries and documents, and the Group-wise Reward/Advantage computation.
Evaluation Highlights
- Achieves 5%–7% improvement in NDCG@10 over baseline BM25 on in-domain datasets (NFCorpus, SciFact, FiQA-2018)
- Significantly outperforms query-augmentation-only and document-augmentation-only baselines, proving the necessity of collaborative training
- Demonstrates strong cross-benchmark generalization: models trained on one dataset improve performance on unseen domains compared to the base Qwen2.5-7B model
Breakthrough Assessment
8/10
Proposes a novel bidirectional RL framework that effectively solves the coordination problem between query and document augmentation, yielding significant gains where single-sided augmentation fails.