📝 Paper Summary
Scaling laws
Factuality and hallucination in LLMs
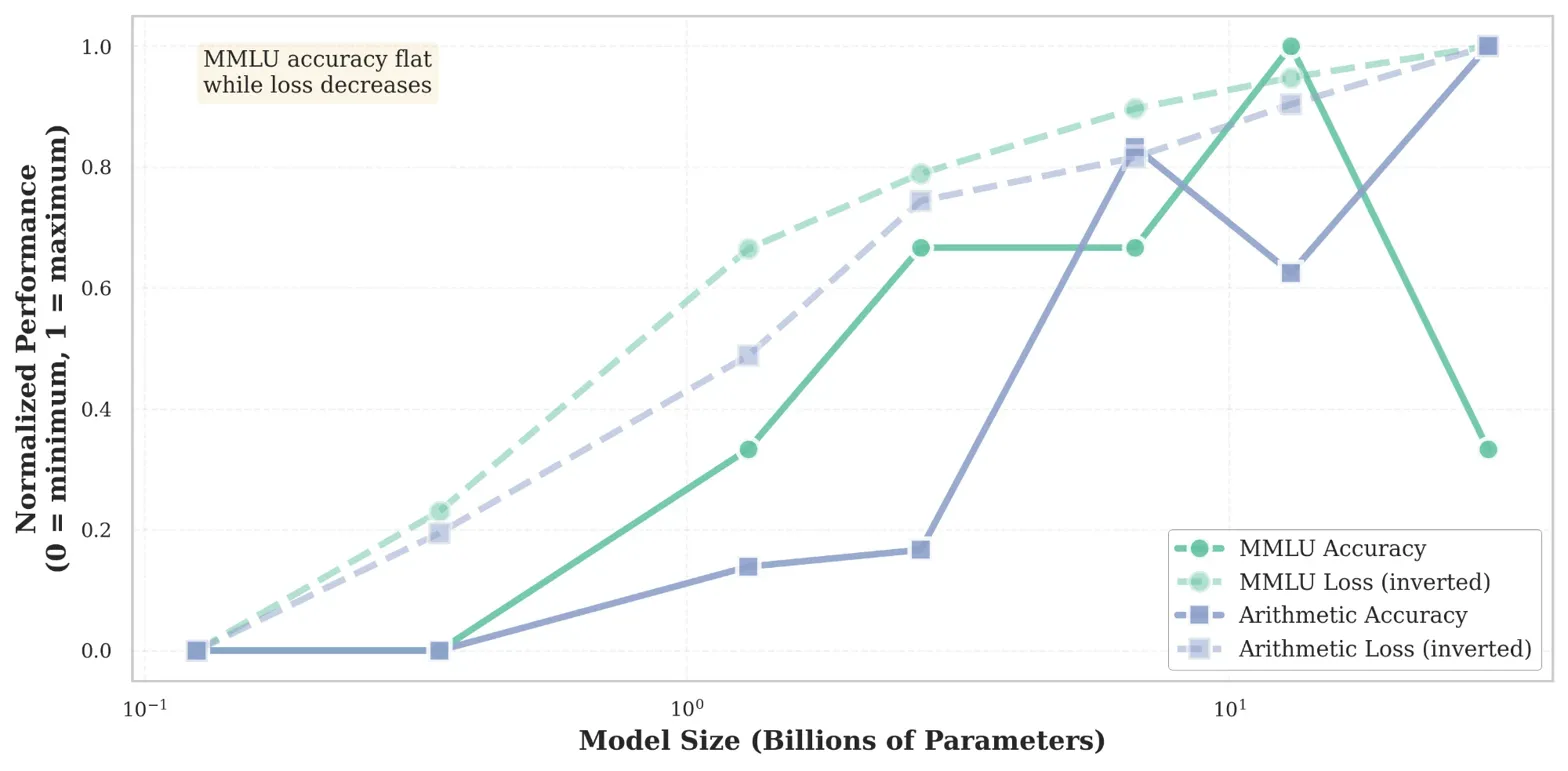
Empirical measurements show that scaling OPT and Pythia models beyond 1-2B parameters yields no accuracy gains on knowledge-intensive benchmarks despite continued loss improvement, revealing a pathological divergence.
Core Problem
Standard neural scaling laws predict that loss improvements lead to better performance, but for knowledge-intensive tasks in decoder-only models, accuracy can stagnate even as loss decreases.
Why it matters:
- Organizations may waste significant compute resources scaling parameters under the false assumption that lower loss guarantees better factual accuracy
- Current evaluation metrics based solely on cross-entropy loss can mask stagnation in actual downstream task capabilities
- Reliance on pure parameter scaling for knowledge tasks in these architectures appears fundamentally limited, necessitating architectural alternatives like retrieval
Concrete Example:
On the MMLU mathematics benchmark, scaling an OPT model from 125M to 30B parameters reduces loss by 31%, yet accuracy remains flat at ~20% (worse than random guessing), meaning the model just becomes more confident in its wrong answers.
Key Novelty
Capability-Specific Scaling Divergence
- Identifies a specific class of tasks (knowledge retrieval) where the correlation between validation loss and task accuracy breaks down completely in decoder-only transformers
- Introduces the 'Confidence-Competence Gap Ratio' to quantify how much a model's prediction confidence improves relative to its actual correctness
- Demonstrates through attention swapping that knowledge capabilities are brittle and tightly coupled to specific attention patterns rather than robust representations
Architecture
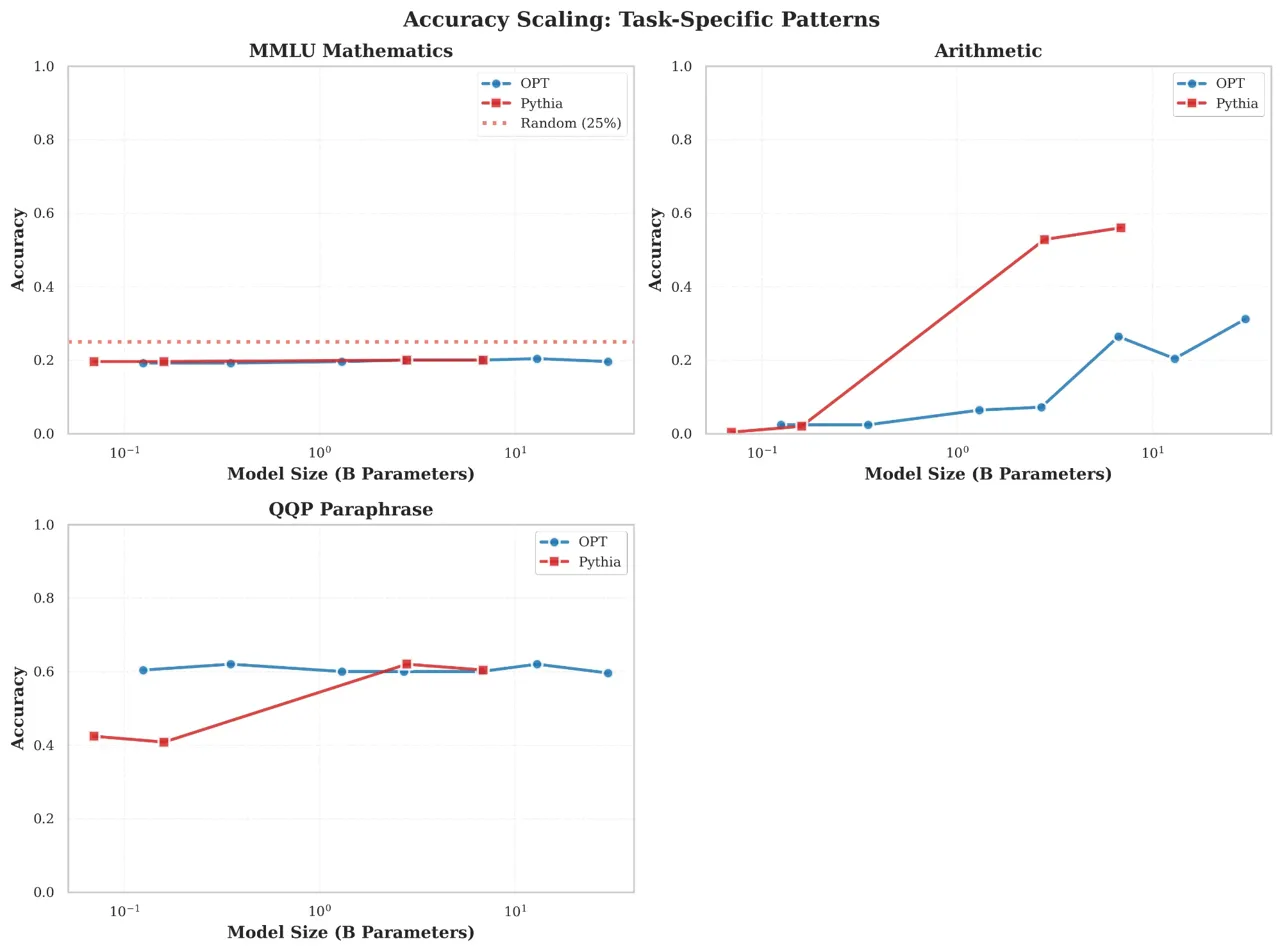
Comparison of scaling trends for MMLU (Knowledge), Arithmetic (Procedural), and QQP (Pattern Matching) across model sizes.
Evaluation Highlights
- MMLU mathematics accuracy remains flat at 19-20% across a 240x parameter scale range (70M to 30B), failing to beat the 25% random chance baseline
- While accuracy stagnates, cross-entropy loss improves by 31% (from 3.1 to 2.1), indicating models learn to confidently generate incorrect answers
- Arithmetic tasks show conventional scaling, improving from 2.4% to 31% accuracy as loss decreases, proving the issue is specific to knowledge tasks
Breakthrough Assessment
7/10
Important negative result challenging the universality of scaling laws for accuracy. While it doesn't propose a new method, the empirical evidence of loss-accuracy divergence is critical for resource allocation.