📝 Paper Summary
Benchmark datasets
Knowledge probing in LLMs
Retrieval-Augmented Generation (RAG) analysis
NanoKnow creates a benchmark by projecting standard QA datasets onto the fully open FineWeb-Edu corpus, allowing researchers to precisely measure how pre-training data presence influences an LLM's knowledge and RAG performance.
Core Problem
It is currently difficult to know if an LLM answers a question because it memorized the answer during pre-training or because it is reasoning over provided context, primarily because pre-training data is usually a 'black box'.
Why it matters:
- Understanding knowledge origins is crucial for distinguishing between memorization and reasoning capabilities
- Researchers cannot accurately evaluate RAG systems without knowing if the model already knows the answer from its training data
- Lack of transparency prevents studying how data frequency affects recall or how parametric knowledge interacts with external evidence
Concrete Example:
If an LLM answers 'Who won the 1996 World Cup?', we don't know if it retrieved that fact from an external document or if it saw that exact sentence 50 times in its private training corpus. NanoKnow solves this by using a model (nanochat) with fully known training data (FineWeb-Edu).
Key Novelty
Transparent Data-Knowledge Mapping
- Partitions existing QA datasets (NQ, SQuAD) into 'supported' (answer exists in pre-training data) and 'unsupported' splits by indexing the exact corpus used for pre-training
- Leverages the fully open nanochat model family and FineWeb-Edu corpus to create a controlled environment where every piece of parametric knowledge can be traced back to specific training documents
Architecture
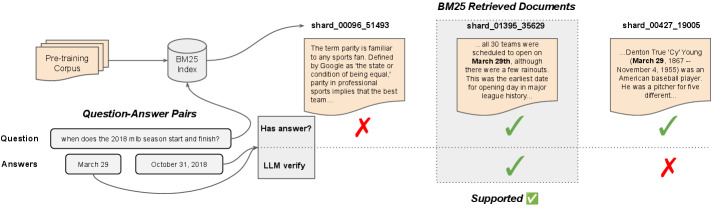
The 3-stage pipeline for constructing the NanoKnow benchmark dataset.
Evaluation Highlights
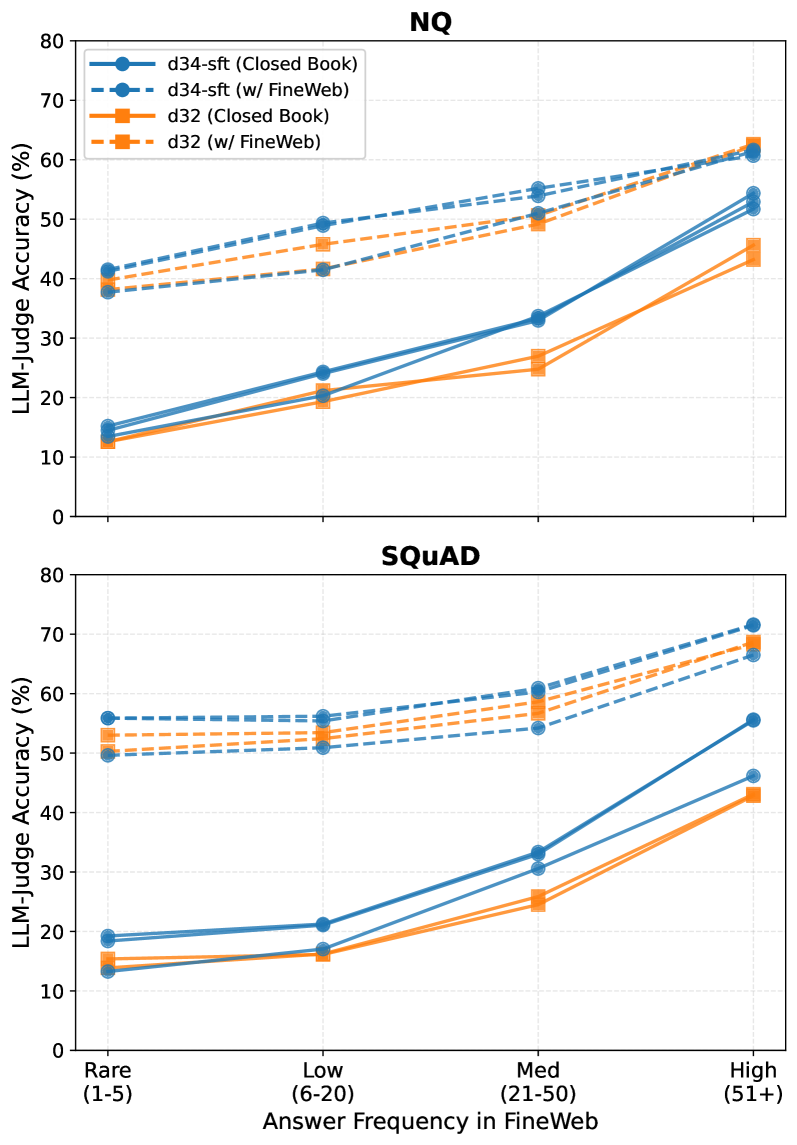
- Closed-book accuracy on Natural Questions roughly doubles for questions with high answer frequency (51+ occurrences) compared to rare answers (1-5 occurrences)
- Providing external evidence (RAG) improves accuracy, but models still perform better on 'supported' questions (+19-25% improvement) than 'unsupported' ones even when given the correct context
- Distractor documents harm performance significantly: accuracy drops by ~11 points when the correct answer is surrounded by 4 distractors compared to 1
Breakthrough Assessment
9/10
Highly significant resource. By aligning open models with open data, it enables precise scientific inquiry into the 'black box' of LLM knowledge that was previously impossible with closed-source models.