📝 Paper Summary
Agentic RAG pipeline
CoRAG jointly optimizes a reranker and generator as cooperative agents using a shared task-oriented reward to eliminate the generator's asymmetric dependency on perfect ranking.
Core Problem
Existing RAG systems use a ranking-centric, asymmetric pipeline where the generator is highly sensitive to reranking errors, requiring the reranker to learn difficult fine-grained orderings.
Why it matters:
- Suboptimal rerankers that misplace relevant documents (even if in the top-N set) can cause generator failure due to strict dependency
- Learning exact total ordering of documents is harder than relaxed ordering, creating an optimization mismatch between reranker difficulty and generator sensitivity
Concrete Example:
If a reranker places a less relevant document at position 1 and the optimal document at position 3, a standard generator might hallucinate an answer based on the first document, even though the correct information is available in the context window.
Key Novelty
Cooperative Retrieval-Augmented Generation (CoRAG)
- Reformulate RAG as a multi-agent problem where reranker and generator are peer decision-makers optimized for a shared final outcome rather than separate metrics
- Transform delayed task rewards (did the answer match?) into document-level stochastic preference signals to train the reranker without explicit relevance labels
Architecture
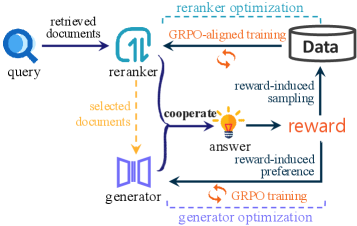
Overview of CoRAG framework showing the interaction between Reranker and Generator and the shared reward mechanism.
Evaluation Highlights
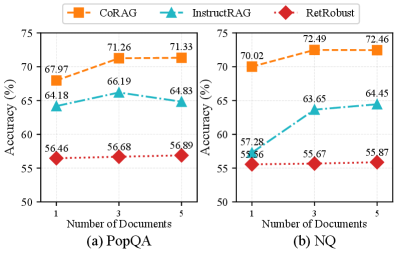
- Achieves 71.2% accuracy on PopQA (trained only on ~10K PopQA samples), significantly outperforming RetRobust and InstructRAG-FT
- Demonstrates strong generalization to unseen datasets: 81.0% accuracy on TriviaQA and 72.4% on Natural Questions without training on them
- Outperforms baselines in code generation (HumanEval pass@1) and table QA (WikiTable Questions), showing cross-domain robustness
Breakthrough Assessment
8/10
Strong performance with limited training data (10K samples) and excellent zero-shot generalization to other datasets suggest the cooperative formulation fundamentally solves the alignment issue in RAG.