📝 Paper Summary
Conversational personalization
Multi-modal generation
This paper enables Multi-modal Large Language Models to perform multi-round personalized image generation by replacing the standard detokenizer with a personalization-enhanced Diffusion Transformer and utilizing a new chat-history caching mechanism.
Core Problem
Existing personalization methods (like DreamBooth or InstantID) operate in single-round settings and lack conversational context, while current MLLMs fail to preserve fine-grained facial identity details due to weak detokenizers.
Why it matters:
- Current diffusion models cannot handle multi-turn interactions, forcing users to restart generation tasks from scratch rather than iterating via dialogue
- Vanilla MLLMs trained on general data struggle to reconstruct specific human identities, limiting their utility for personalized creative applications
- No existing datasets support the development of models that need to reason across interleaved text-image chat history for consistent character generation
Concrete Example:
In a chat, a user generates an image of 'Olivia' in Round 1. In Round 2, the user asks for 'a close-up of Olivia' without re-describing her. Standard models fail because they cannot retrieve 'Olivia's' visual features from the Round 1 history to inform Round 2 generation.
Key Novelty
Conversational MLLM with DiT Detokenizer
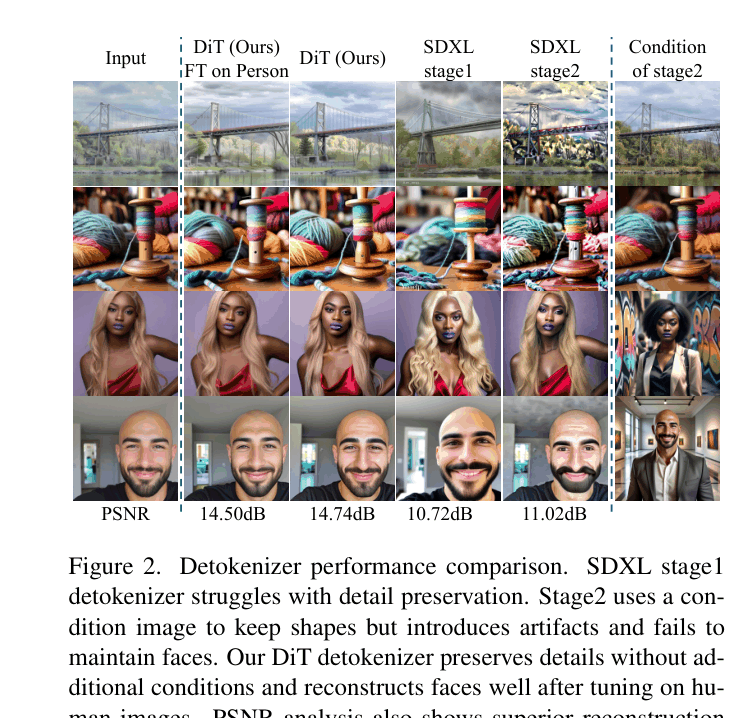
- Identifies that standard VQGAN-like detokenizers in MLLMs bottleneck identity preservation, and replaces them with a Diffusion Transformer (DiT) specifically fine-tuned on human faces to reconstruct fine details from image tokens
- Implements a chat-history caching mechanism that allows the MLLM to attend to past visual outputs and textual descriptions, enabling consistent character generation across multiple dialogue turns without re-prompting
Architecture
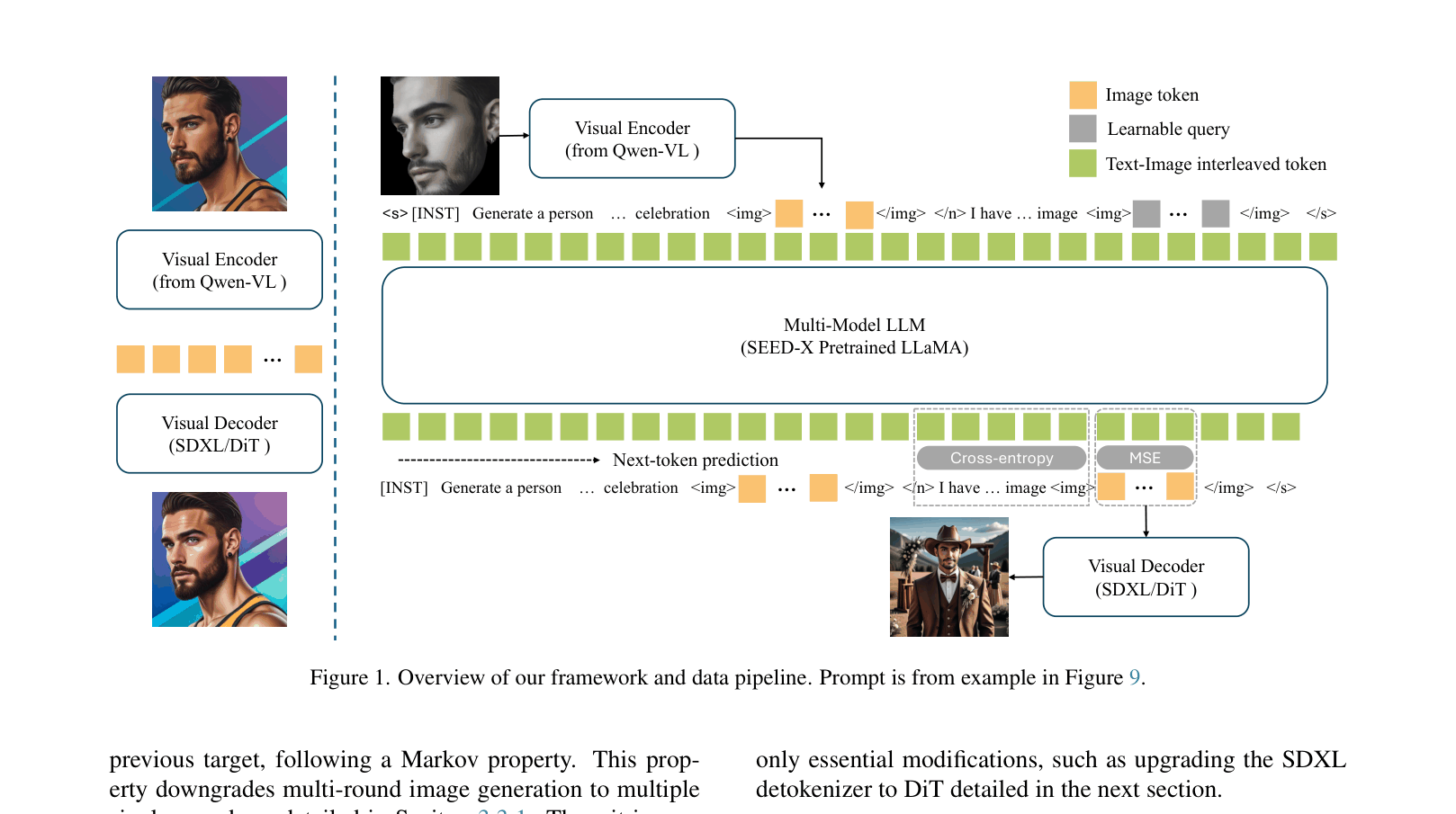
Overview of the framework and data pipeline, showing the MLLM processing interleaved text/image tokens and the Visual Decoder reconstructing the image.
Evaluation Highlights
- Achieves 0.293 ArcFace score (identity similarity) in single-round personalization, significantly outperforming the base SEED-X model's score of 0.094
- Human evaluation shows a 73.75% preference for the proposed method's image quality over SEED-X
- 71.25% human preference win rate for Face Identity preservation compared to the SEED-X baseline
Breakthrough Assessment
8/10
First work to enable true multi-round conversational personalization where an MLLM retrieves visual identity from chat history. Significant architectural improvement (DiT detokenizer) addresses a major MLLM bottleneck.