📝 Paper Summary
LLM-as-a-judge
Reward Modeling
Reinforcement Fine-Tuning (RFT)
RRD improves LLM judging and reward modeling by recursively decomposing coarse rubrics into fine-grained criteria and filtering out redundant or misaligned signals to create comprehensive, low-noise evaluations.
Core Problem
Existing rubric-based judges suffer from coverage deficiency (missing nuanced criteria) and noisy evaluation (redundant or misaligned rubrics), leading to poor agreement with human preferences and unstable reward signals.
Why it matters:
- Naive rubric generation degrades GPT-4o's judgment accuracy by 13 points below using no rubrics at all on JudgeBench
- Limited rubric quality bottlenecks Reinforcement Learning from Verifiable Rewards (RLVR) in open-ended domains where rewards are non-verifiable
- Poorly defined rubrics produce suboptimal reward signals during reinforcement fine-tuning (RFT), limiting model alignment gains
Concrete Example:
Naively generated rubrics degrade GPT-4o's accuracy on JudgeBench to 42.9%, significantly worse than the 55.6% base accuracy, because generic criteria fail to capture the specific nuances distinguishing high-quality responses.
Key Novelty
Recursive Rubric Decomposition (RRD)
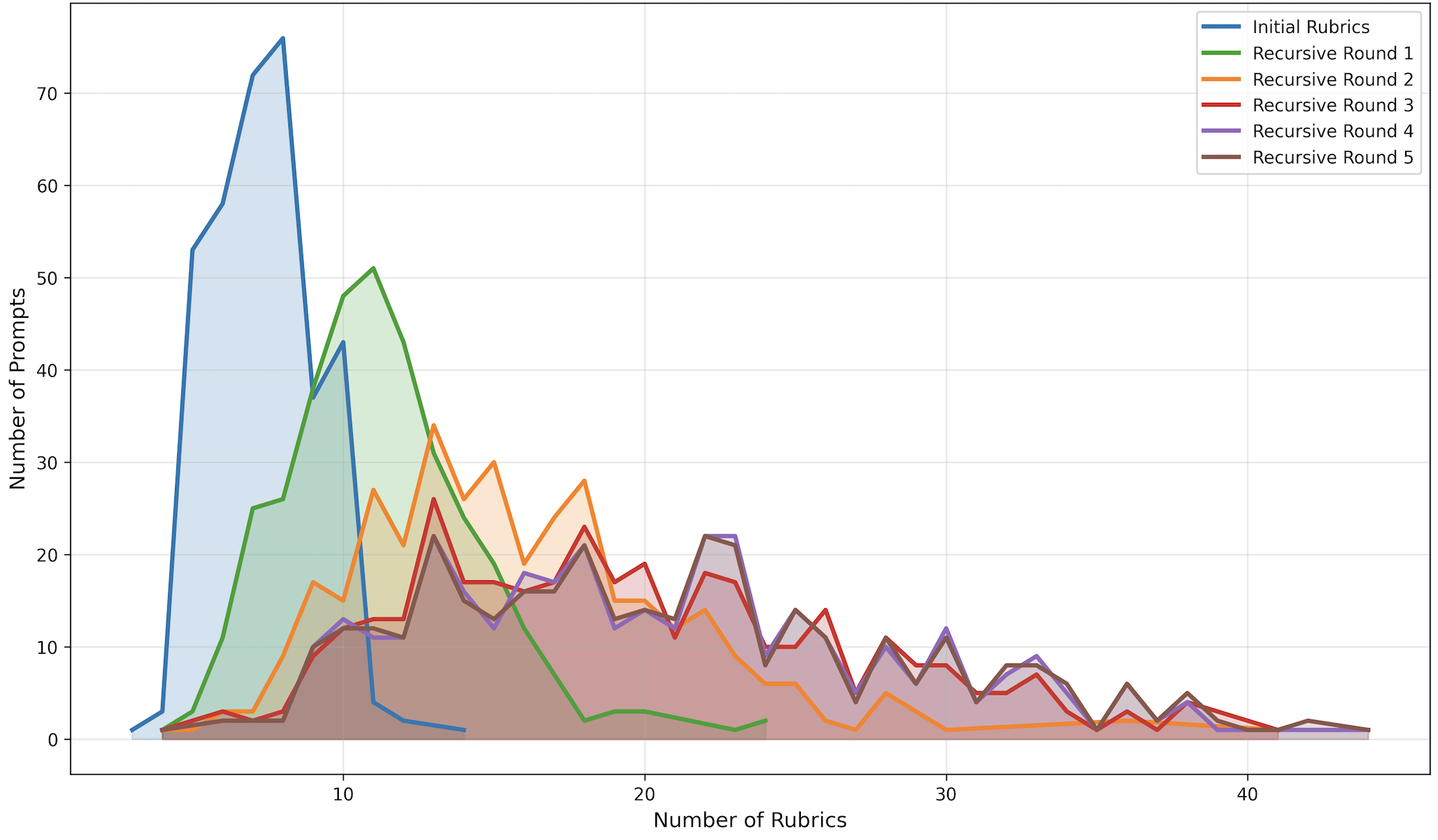
- Recursively decomposes rubrics that are 'too broad' (satisfied by multiple diverse responses) into finer-grained sub-criteria until they discriminate effectively between candidates
- Filters out misaligned rubrics (that prefer weaker models over stronger ones) and redundant ones to maintain a high signal-to-noise ratio
- Uses a 'whitened' weighting scheme that down-weights correlated rubrics without needing ground-truth labels, preventing overlapping criteria from dominating the final score
Architecture
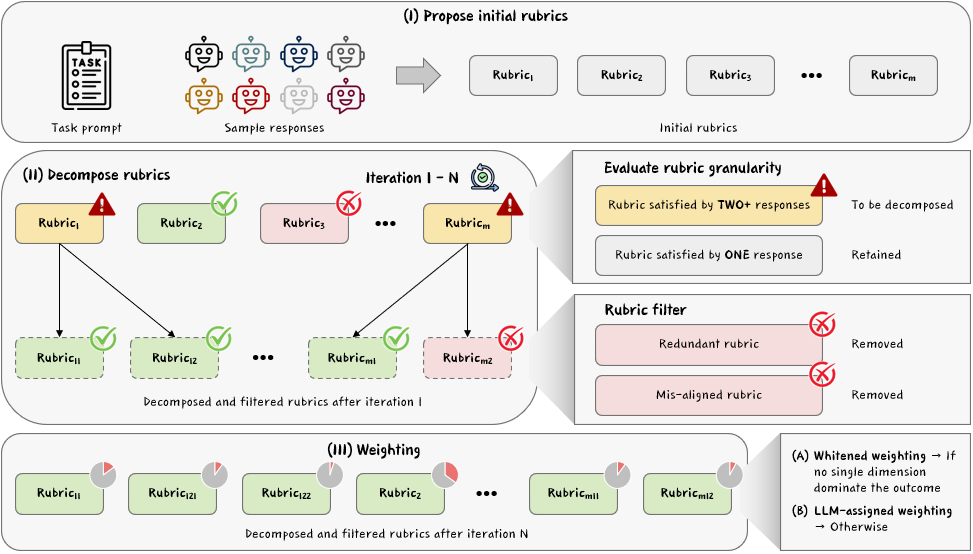
The Recursive Rubric Decomposition (RRD) workflow.
Evaluation Highlights
- Improves GPT-4o preference-judgment accuracy on JudgeBench by +17.7 points (55.6% → 73.3%), achieving top performance
- Boosts reward during Reinforcement Fine-Tuning by up to 160% for Qwen3-4B and 60% for Llama3.1-8B on WildChat compared to ~10-20% for baselines
- Consistent gains transfer to downstream benchmarks like HealthBench-Hard and BiGGen Bench for RFT-trained policies
Breakthrough Assessment
8/10
Offers a theoretically grounded and empirically strong solution to the brittleness of LLM judges. Significant gains in both evaluation accuracy and downstream RFT effectiveness suggest it solves a key bottleneck in open-ended alignment.