📝 Paper Summary
Agentic AI
Safety & Robustness
TrajAD is a generative verifier that detects and precisely localizes anomalies in agent execution trajectories, enabling efficient rollback-and-retry recovery instead of full restarts.
Core Problem
Current agent safety measures focus on static input/output filtering or capability enhancement, failing to detect runtime process anomalies like infinite loops, redundant actions, or intermediate reasoning errors.
Why it matters:
- Unverified intermediate steps can trigger irreversible state changes (e.g., database corruption) even if the final output seems plausible
- Blindly restarting failed tasks wastes computational resources; agents need to know exactly *where* they failed to rollback efficiently
- General-purpose LLMs struggle to distinguish between complex reasoning and redundant loops without specific process supervision
Concrete Example:
An agent might enter an infinite loop or execute redundant actions that are locally plausible but globally inefficient. Standard outcome-based evaluations miss this if the task eventually completes, while static guardrails fail to catch the temporal inefficiency.
Key Novelty
Generative Trajectory Verifier with Step-Level Localization
- Formulates anomaly detection as a conditional generation task where the model outputs both a verdict (Normal/Anomaly) and the exact index of the first error step
- Synthesizes a large-scale dataset (TrajBench) using a 'Perturb-and-Complete' strategy to create paired normal/anomalous trajectories with precise ground-truth error labels
- Enables a 'Check-and-Act' runtime monitor that interrupts faulty execution and triggers targeted rollbacks
Architecture
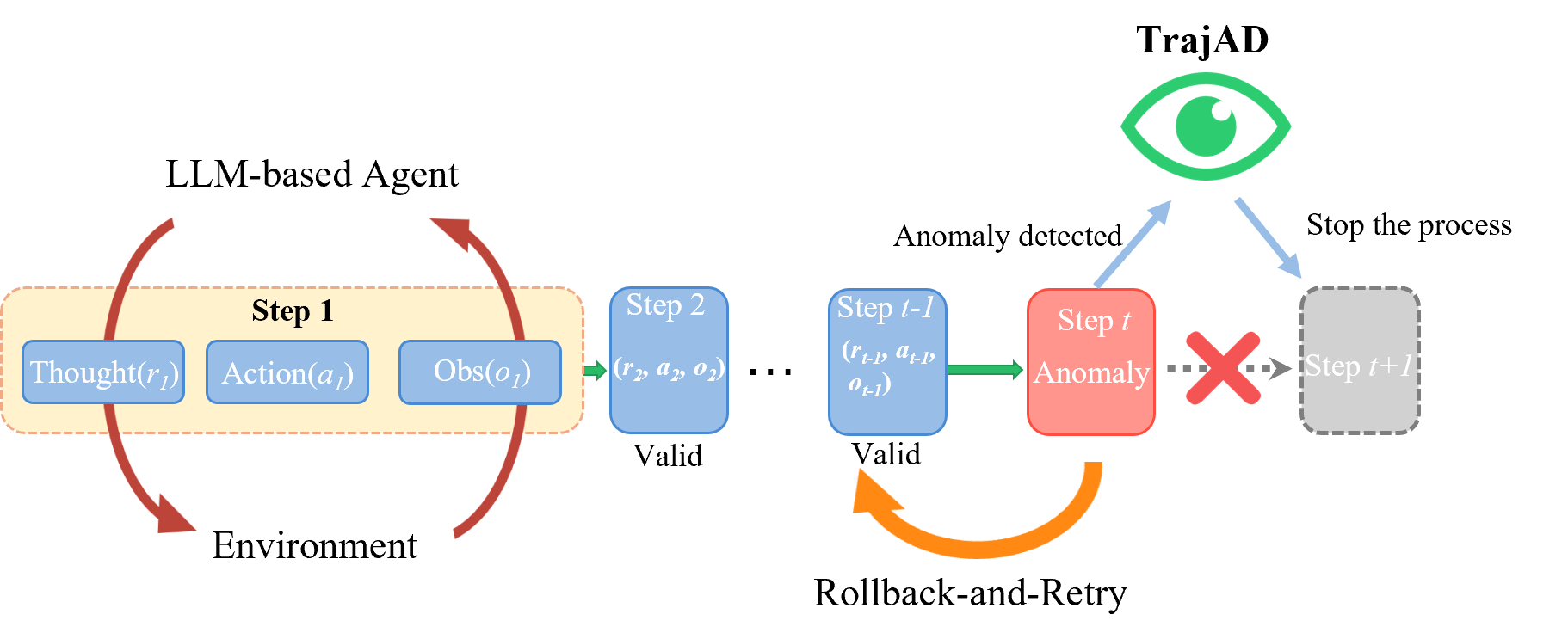
The TrajAD framework workflow, illustrating the runtime monitoring process.
Evaluation Highlights
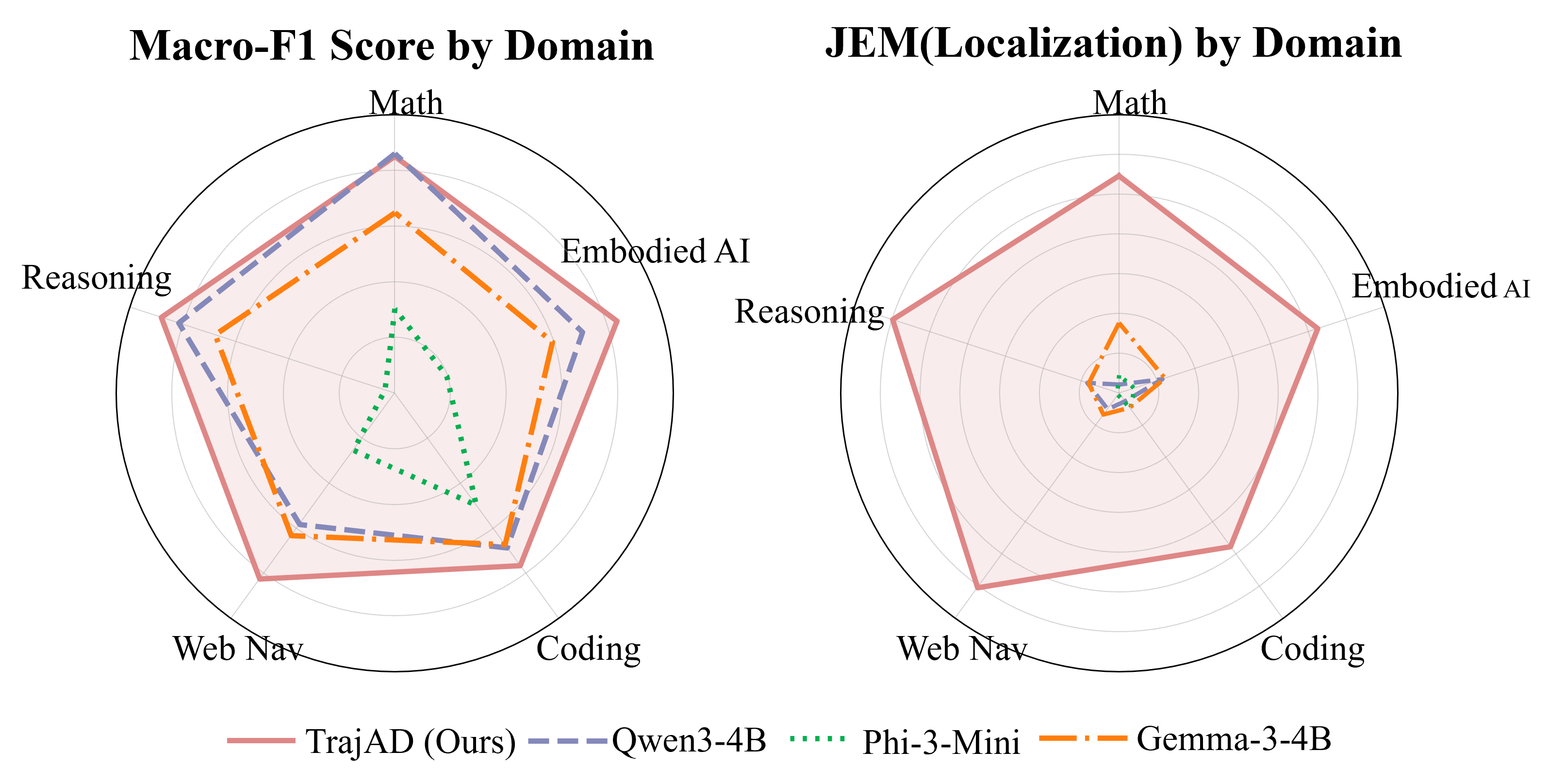
- Outperforms strong zero-shot baselines (Qwen3-8B) by +11.38% in Macro-F1 for anomaly detection
- Achieves a massive +48.21% improvement in Joint Exact Match (JEM) for error localization compared to baselines, which often fail to pinpoint the error step
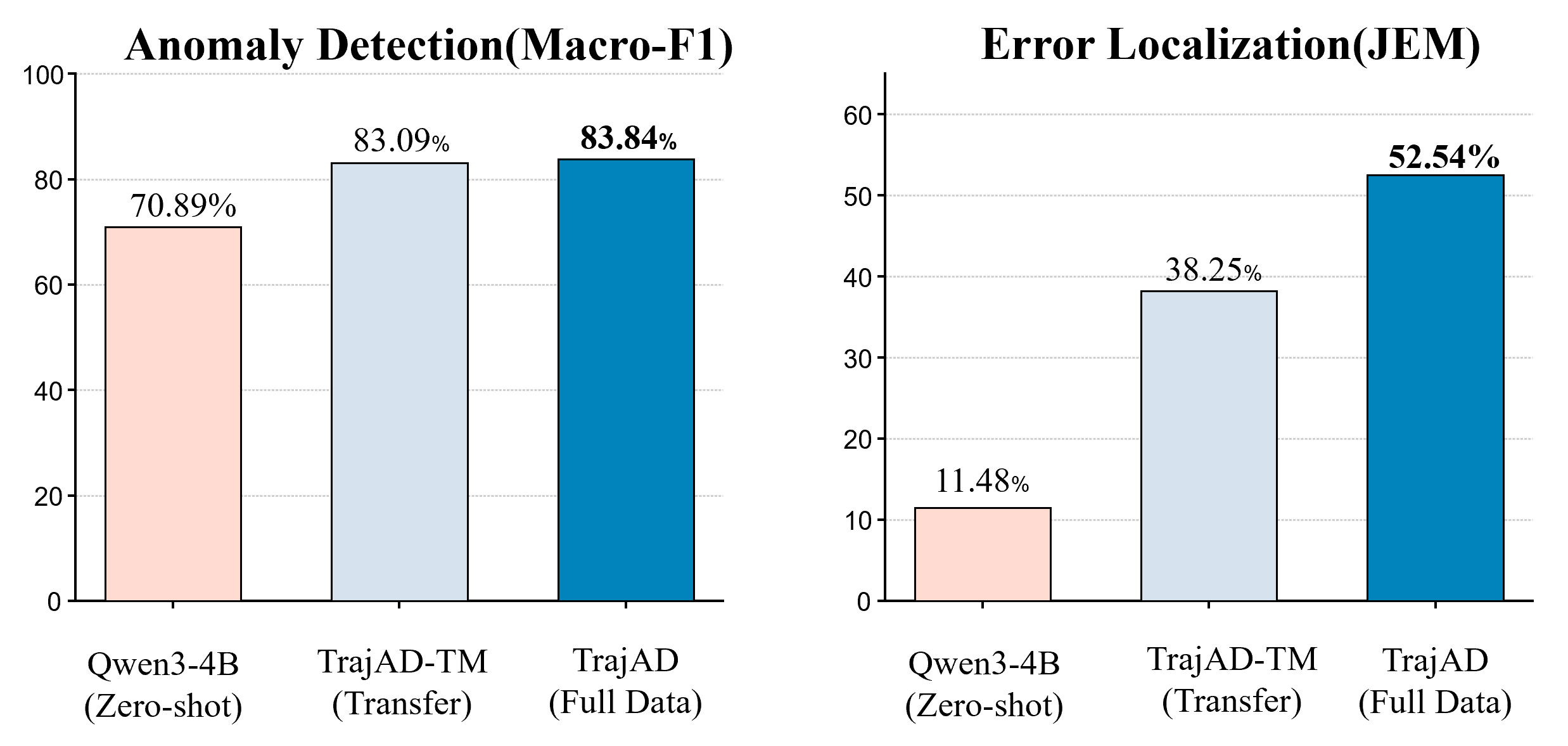
- Demonstrates strong transferability to unseen domains (e.g., Embodied AI), improving Macro-F1 from 70.89% (zero-shot) to 83.09%
Breakthrough Assessment
7/10
Significant step forward in process supervision for agents. The shift from outcome-based to process-based verification with precise localization is critical for practical deployment.