📝 Paper Summary
LLM Security
Model Protection
Knowledge Distillation Defense
The paper proposes rewriting teacher model reasoning traces using optimized instructions or gradient-based methods to either degrade student training efficacy or embed verifiable watermarks without harming teacher performance.
Core Problem
Unauthorized knowledge distillation allows third parties to steal the capabilities of expensive frontier models by training student models on their outputs.
Why it matters:
- Frontier reasoning models require enormous cost and effort to develop, and unauthorized cloning disincentivizes innovation.
- Existing anti-distillation methods (like sampling or post-training) degrade the teacher's own utility or produce unnatural text.
- Current API watermarking methods often rely on token statistics that yield high false alarm rates.
Concrete Example:
A 'thief' queries a proprietary model like GPT-4 with complex math problems, records the step-by-step solutions, and fine-tunes a smaller Llama model on them. The proposed system rewrites the GPT-4 steps on-the-fly so they look correct to humans but confuse the student model during training.
Key Novelty
Trace Rewriting for Anti-Distillation and Watermarking
- Instruction-based rewriting: Uses an assistant LLM with optimized prompts to rewrite reasoning traces, preserving semantics while making them hard for students to learn from.
- Gradient-based rewriting: Modifies token embeddings to maximize a proxy student's loss, then projects back to discrete tokens (though less effective than the instruction approach).
- Zero-false-alarm watermarking: Injects specific trigger-target patterns into reasoning traces via rewriting, allowing reliable verification with minimal queries.
Architecture
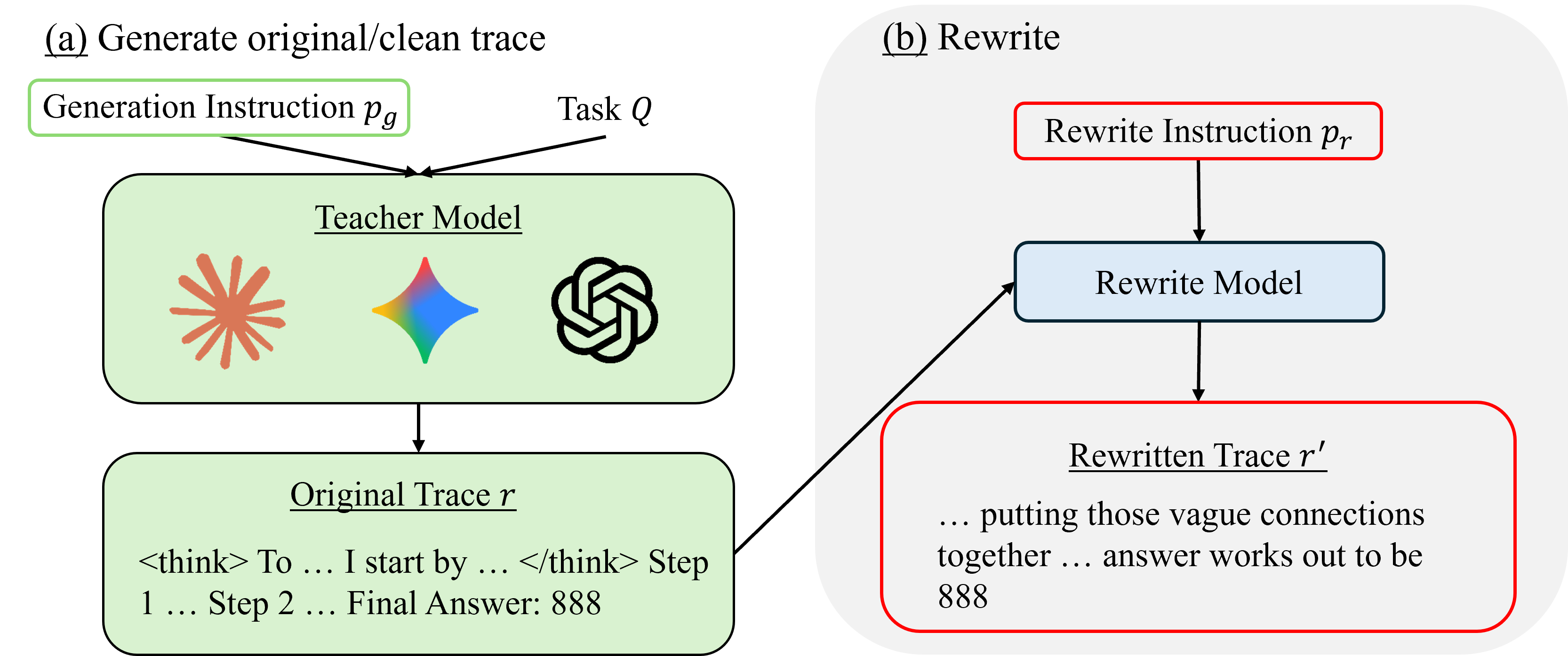
The overall framework for Anti-Distillation and Watermarking via trace rewriting.
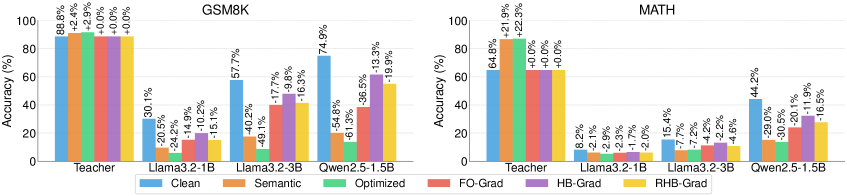
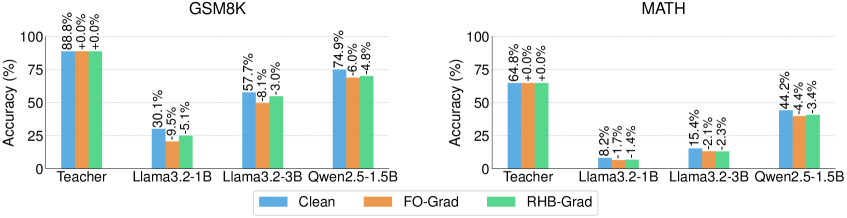
Evaluation Highlights
- Instruction-based anti-distillation reduces student accuracy by up to 61.3% (relative to clean baseline) on the GSM8K benchmark.
- The proposed method maintains or improves teacher accuracy (e.g., +0.5% on GSM8K), whereas baselines like ADS degrade teacher accuracy by ~4-14%.
- Watermarking achieves 100% detection rate with 0% false positive rate using only ~10 verification queries.
Breakthrough Assessment
8/10
Significantly improves upon prior anti-distillation methods by decoupling defense from teacher degradation. The zero-false-alarm watermarking result is particularly strong compared to statistical baselines.