📝 Paper Summary
LLM Alignment
Confidence Calibration
CATTO integrates a differentiable, token-level calibration loss directly into preference optimization (like DPO) to prevent the confidence drift that typically occurs during alignment.
Core Problem
Preference alignment methods like DPO optimize relative likelihoods but leave absolute probability scales unconstrained, causing models to become severely miscalibrated (overconfident in wrong answers, underconfident in right ones).
Why it matters:
- LLMs are increasingly deployed in decision-making settings (medical, legal) where reliable confidence estimates are critical for safety and trust.
- Post-hoc calibration methods (like temperature scaling) do not persist after further training, and existing training-time methods do not survive the logit drift caused by preference optimization.
- Current alignment techniques break the link between a model's predictive probability and its actual correctness frequency.
Concrete Example:
After DPO alignment, a model might predict an incorrect answer with 99% confidence because the optimization pushed logits to extreme values to satisfy preference pairs, whereas a well-calibrated model would assign it a low probability reflecting its true uncertainty.
Key Novelty
Calibration Aware Token-level Training Objective (CATTO)
- Introduces a differentiable surrogate for Expected Calibration Error (ECE) that operates per-token, allowing calibration to be optimized via gradient descent.
- Combines this calibration loss linearly with the standard DPO objective, constraining absolute confidence levels while simultaneously optimizing for human preferences.
- Uses a margin-based correctness surrogate (difference between ground truth and best incorrect token) to provide a smooth training signal for calibration.
Architecture
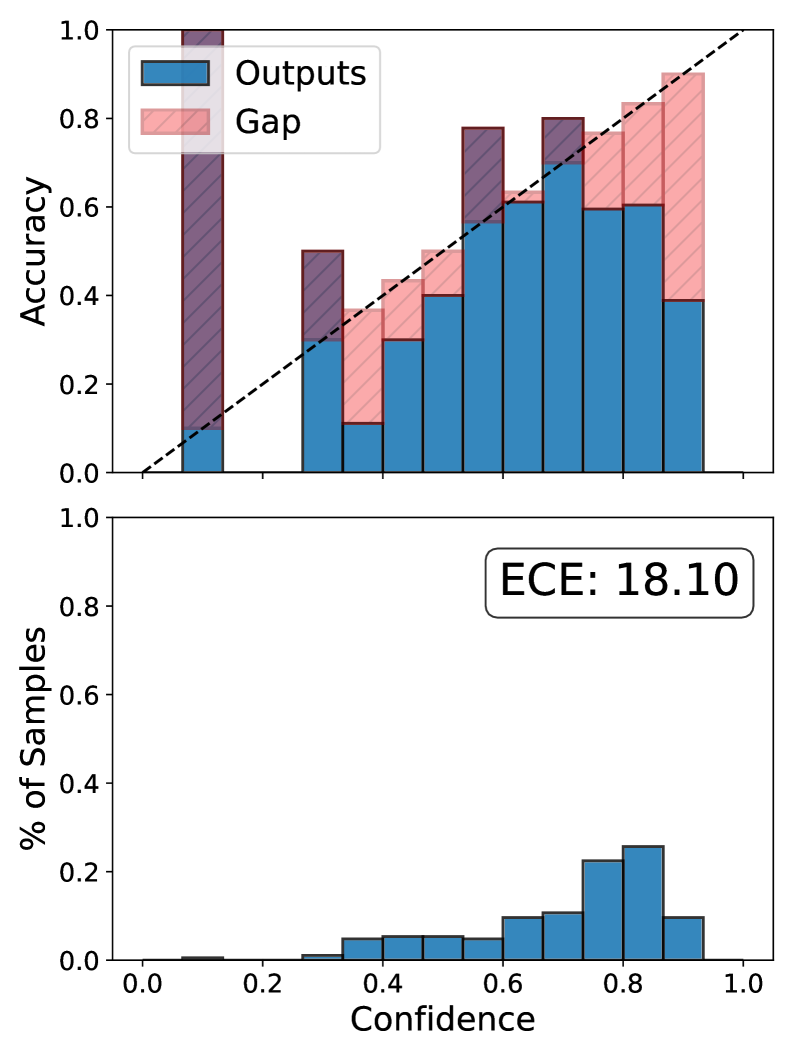
Conceptual illustration of miscalibration in DPO vs. CATTO.
Evaluation Highlights
- Reduces Expected Calibration Error (ECE) by 2.22%-7.61% compared to standard DPO on in-distribution benchmarks.
- Outperforms the strongest DPO baseline (RCFT) by 0.22%-1.24% in ECE while requiring significantly less compute.
- Maintains or improves downstream accuracy (+3.16% average) across five datasets, unlike other calibration methods that often trade off accuracy.
Breakthrough Assessment
8/10
Offers a principled, theoretically grounded solution to the known problem of miscalibration in RLHF/DPO. The method is efficient (no extra parameters) and effective, addressing a critical safety/reliability gap.