📝 Paper Summary
Tool-use post-training
Data synthesis for tool learning
KG2Tool generates high-quality tool-use instruction data by mapping Knowledge Graph relations to APIs and extracting First-Order Logic query pathways as ground-truth solution steps.
Core Problem
Current methods for training LLMs to use tools rely on costly human annotation or unstable LLM-generated data, often resulting in errors, low complexity, and hallucinated solution paths.
Why it matters:
- LLM-generated tool data often contains irrelevant tool combinations or incorrect logic, requiring expensive manual verification
- Simple prompting strategies produce low-complexity queries that fail to challenge the model's reasoning capabilities
- High-quality, verifiable execution traces are essential for robust tool learning but are hard to scale with human annotators
Concrete Example:
A standard LLM might generate a query asking about a researcher but hallucinate a non-existent API or return incorrect data. In contrast, this method extracts a verifiable fact chain from a KG—e.g., 'Turing Award winners -> work in -> Deep Learning'—and converts it into an executable API sequence ('get_winners', 'get_intersection') where the ground truth is guaranteed by the graph structure.
Key Novelty
KG-to-Tool Instruction Synthesis (KG2Tool)
- Treats Knowledge Graph triples (Head, Relation, Tail) as functional API calls (Input, Function, Output), guaranteeing execution correctness without an external interpreter
- Uses First-Order Logic (FOL) templates to sample complex, multi-step subgraph structures, ensuring diverse and logic-heavy query patterns
- Generates solution paths by traversing these subgraphs, providing accurate intermediate execution steps for instruction tuning without running actual code
Architecture
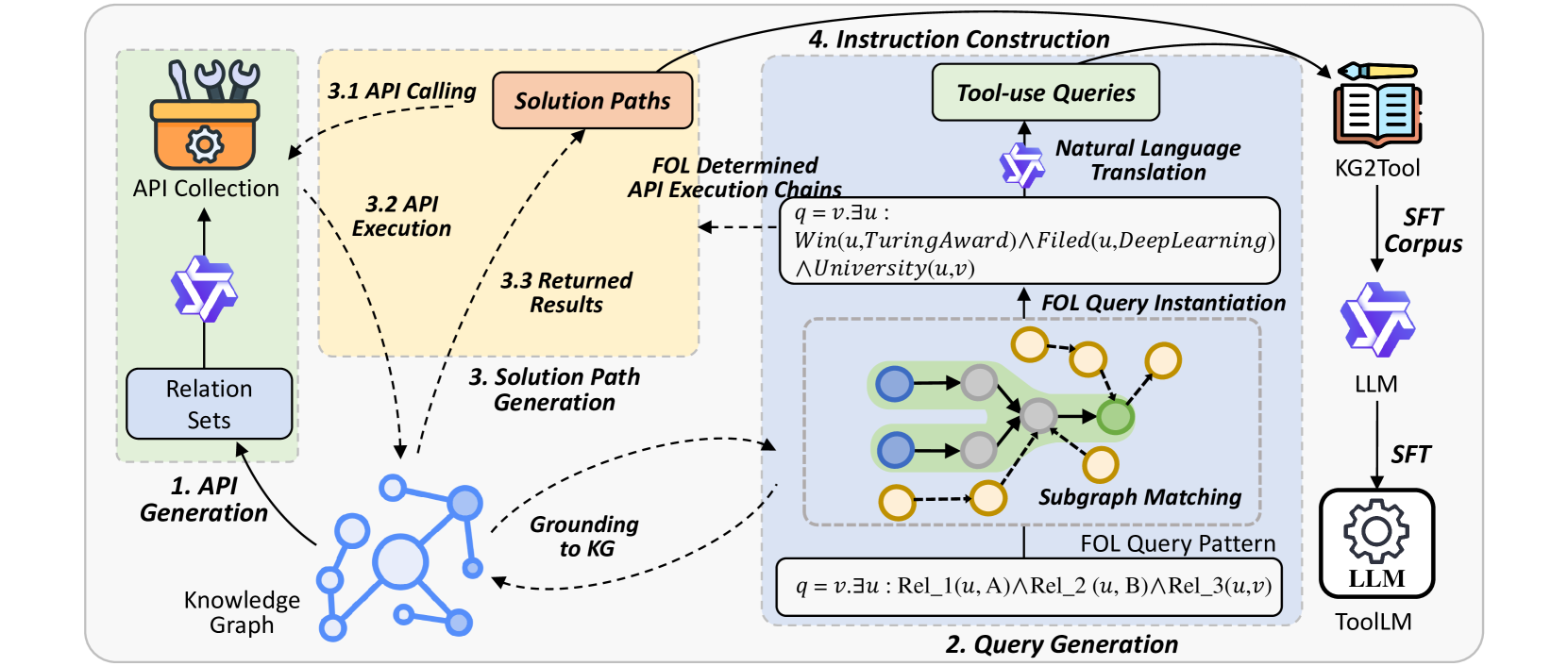
The overall framework for generating instruction data from Knowledge Graphs. It shows the pipeline from KG subgraph sampling to instruction formatting.
Evaluation Highlights
- ToolLM-14B achieves 87.21 overall score on T-Eval, outperforming the much larger Qwen2.5-72B (86.71) and GPT-4 (86.44)
- ToolLM-7B improves by 9.0% over its base model Qwen2.5-7B, surpassing GPT-3.5 (84.05 vs 84.72)
- Fine-tuning on just 2,000 synthetic samples yields significant gains, demonstrating high data efficiency compared to larger, noisier datasets
Breakthrough Assessment
7/10
Highly effective method for generating verifiable tool-use data without external APIs. While the scope is limited to KG-style lookup tasks, the performance gains on general benchmarks like T-Eval are impressive for such a small dataset.