📝 Paper Summary
Video-Language Models (Video-LLMs)
Parameter-Efficient Fine-Tuning (PEFT)
ViPE replaces long visual token sequences with learnable perceptual weights injected directly into the LLM's parameters, enabling efficient long-video understanding without visual tokens at inference.
Core Problem
Existing Video-LLMs concatenate visual tokens with text, causing computational costs to scale quadratically with video length due to the LLM's self-attention mechanism.
Why it matters:
- Long videos (e.g., 10K frames) would require millions of visual tokens, exceeding current model context limits
- Standard approaches face severe latency and memory bottlenecks during inference when processing dense visual inputs
- Simple compression strategies often degrade temporal coherence and semantic richness for long-range video modeling
Concrete Example:
Processing a video with 10K frames using LLaVA would generate over 5.7 million visual tokens. This massive sequence length makes real-time inference or even loading the context impossible for standard LLMs.
Key Novelty
Video-to-Parameter Alignment Paradigm
- Instead of feeding visual tokens as input to the LLM, transform video features into low-rank weight updates (perceptual weights) added to the LLM's weights
- Use a hierarchical merge strategy to compress redundant visual frames into compact queries before generating these weights
- Allows the LLM to 'see' the video by modifying its internal processing logic rather than reading a long description of it
Architecture
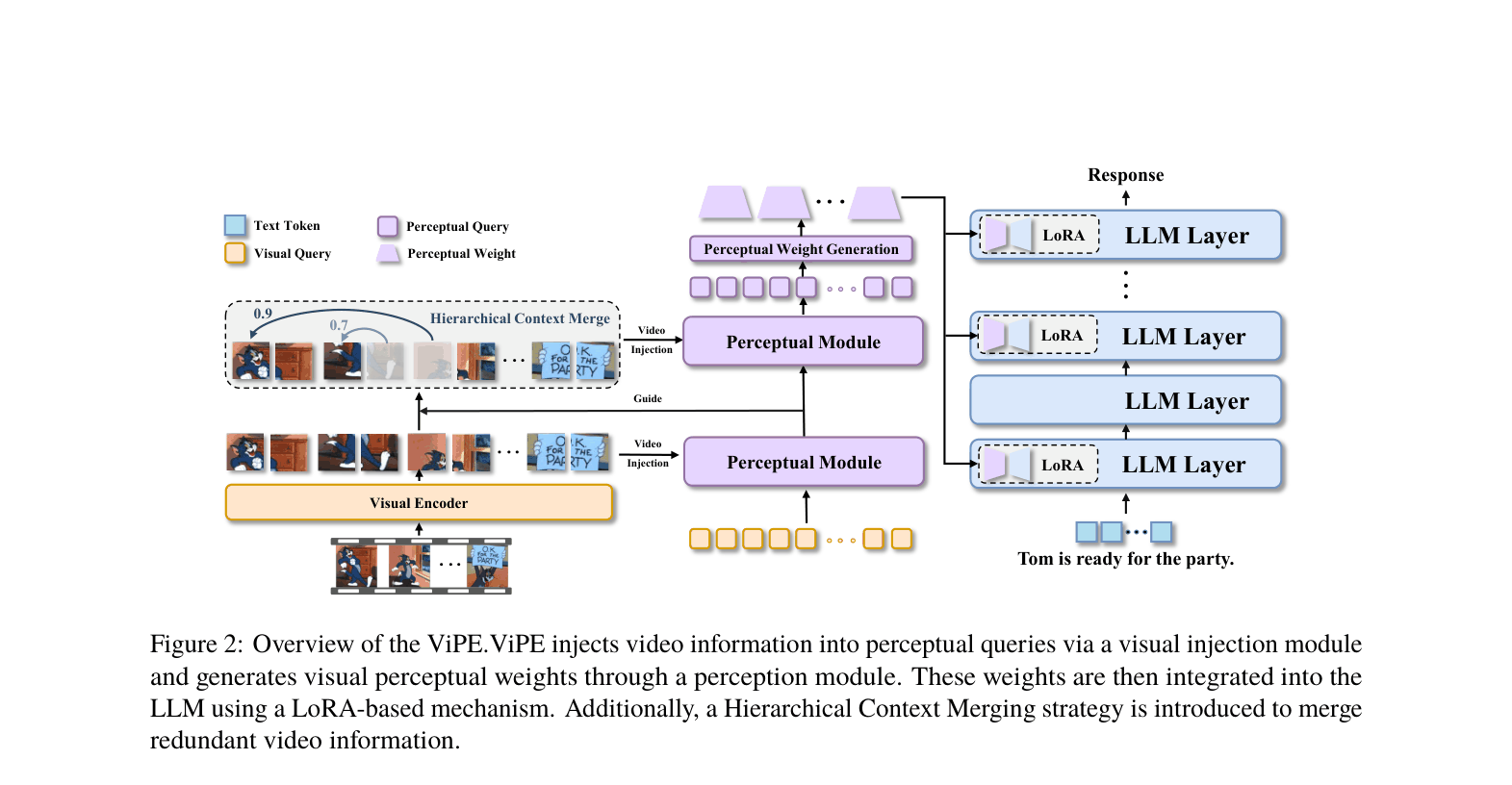
Overview of ViPE architecture showing the Visual Injection Module and Visual Perception Module integrating with the LLM via LoRA.
Evaluation Highlights
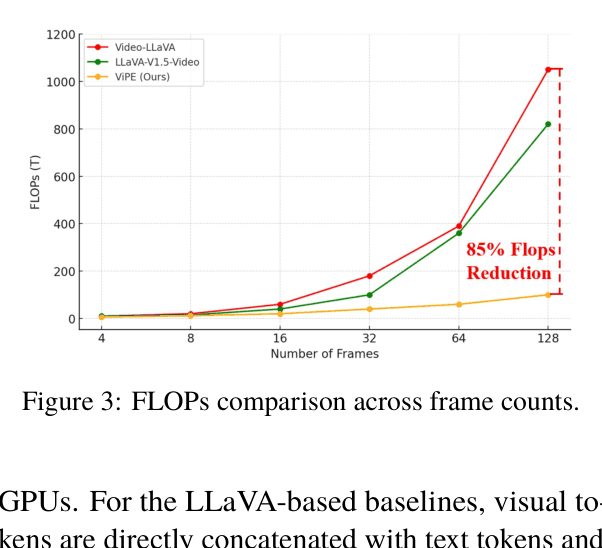
- Reduces FLOPs by 85% and inference time by 65% compared to LLaVA-style baselines while maintaining comparable performance
- Outperforms token-based Video-LLaVA on 5 long-video benchmarks (e.g., +12.8% on EgoSchema)
- Maintains stable performance even when merging 60% of visual context, demonstrating high efficiency
Breakthrough Assessment
8/10
Significant efficiency breakthrough for long videos. shifting from token-based to parameter-based alignment is a novel and effective paradigm shift for multimodal LLMs.