📝 Paper Summary
Multi-Agent Reinforcement Learning
LLM Post-training
Agent Orchestration
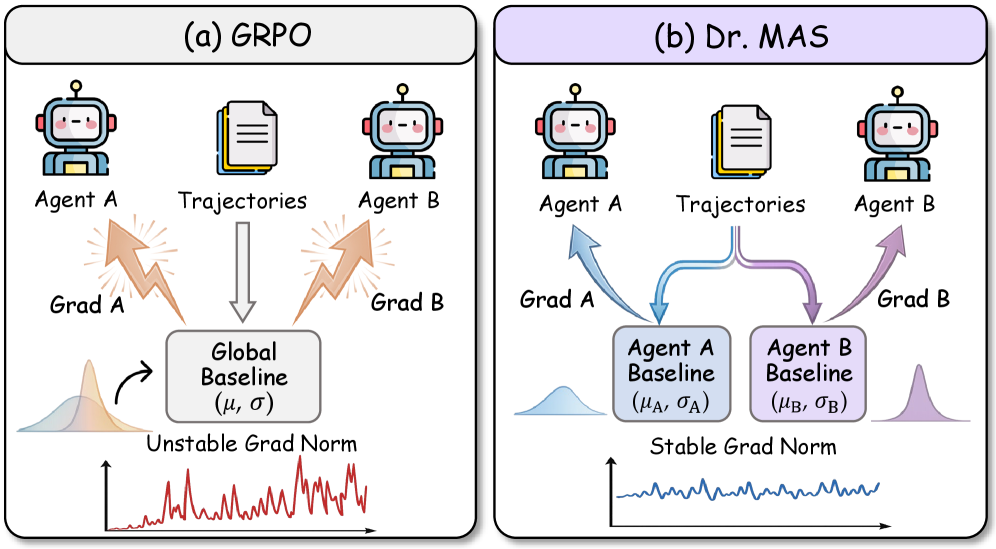
Dr. MAS stabilizes multi-agent reinforcement learning by normalizing advantages per agent rather than globally, preventing gradient spikes caused by diverse reward distributions among specialized agents.
Core Problem
Applying group-based RL (like GRPO) to multi-agent systems is unstable because a global normalization baseline fails when agents have heterogeneous reward distributions.
Why it matters:
- Specialized agents (e.g., planners vs. executors) naturally operate in different reward ranges; forcing a global mean causes gradient explosions.
- Current frameworks (veRL, ROLL) lack native support for efficient multi-agent orchestration and shared resource scheduling for co-training multiple LLMs.
- Instability prevents effective post-training of complex multi-agent systems required for advanced reasoning and tool-use tasks.
Concrete Example:
In a search task, a 'Search' agent might receive lower average rewards than an 'Answer' agent. Using a global mean, the Search agent's updates are consistently biased, inflating gradient norms and causing the model to collapse (e.g., Qwen2.5-7B stops calling search tools entirely).
Key Novelty
Agent-Wise Advantage Normalization (Dr. MAS)
- Instead of normalizing rewards using a global group mean/variance, each agent normalizes its advantages using only its own reward statistics.
- This theoretically bounds the second moment of the gradient for each agent, eliminating the variance inflation caused by reward distribution shifts between agents.
Architecture
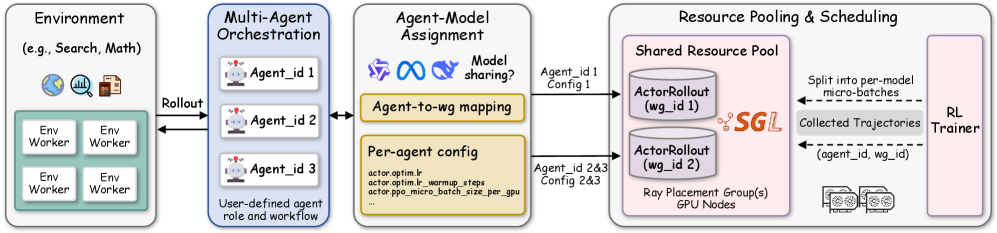
The Dr. MAS system framework including orchestration, resource pooling, and agent-wise optimization.
Evaluation Highlights
- +5.6% avg@16 and +4.6% pass@16 improvement on math reasoning benchmarks over vanilla GRPO using Qwen3 models.
- +15.2% avg@16 and +13.1% pass@16 improvement on multi-turn search tasks over vanilla GRPO using Qwen2.5 models.
- Restores performance of Qwen2.5-7B in non-shared search settings (from 28.0% to 43.8%), whereas vanilla GRPO collapsed due to gradient instability.
Breakthrough Assessment
8/10
Identifies a fundamental theoretical flaw in applying GRPO to multi-agent settings and provides a simple, rigorous fix that yields significant stability and performance gains.