📝 Paper Summary
Agentic RAG pipeline
Reinforcement Learning for RAG
ReasonRAG improves agentic RAG by using Monte Carlo Tree Search to generate high-quality process-level supervision data, enabling an LLM to learn efficient multi-step retrieval and reasoning via Direct Preference Optimization.
Core Problem
Existing agentic RAG systems relying on outcome-supervised reinforcement learning suffer from low exploration efficiency, sparse rewards, and gradient conflicts because they only receive feedback after the final answer.
Why it matters:
- Outcome-based supervision penalizes entire reasoning chains even if early steps were correct, leading to inefficient learning
- High-quality process-level annotation is prohibitively expensive to obtain manually
- Current systems struggle with complex multi-step queries requiring dynamic retrieval decisions
Concrete Example:
In outcome-based RL (like Search-R1), if a model makes a correct search query but fails the final synthesis, the valid search action is penalized. ReasonRAG provides rewards for the intermediate search step.
Key Novelty
Process-Supervised RL with MCTS-generated Data (ReasonRAG)
- Uses Monte Carlo Tree Search (MCTS) to explore possible RAG trajectories (query generation, evidence extraction, answering) and discover high-quality paths
- Introduces Shortest Path Reward Estimation (SPRE) to automatically assign rewards to intermediate steps, prioritizing correctness and efficiency (shorter paths)
- Compiles these paths into a process-level preference dataset (RAG-ProGuide) to train the policy via DPO
Architecture
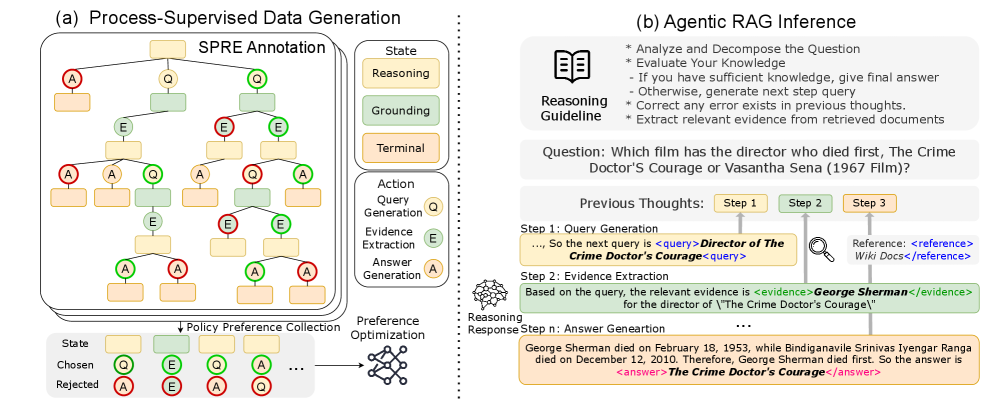
The ReasonRAG framework illustrating (a) Process-Supervised Data Construction via MCTS and SPRE, and (b) The Agentic RAG Inference workflow.
Evaluation Highlights
- Outperforms Search-R1 on HotpotQA (48.9% vs 47.0% F1) using only 5k training queries compared to Search-R1's 90k
- Achieves higher average performance (34.4% EM, 42.3% F1) across 5 benchmarks compared to Search-R1 (32.8% EM, 40.7% F1)
- Demonstrates strong out-of-domain generalization, beating baselines on Bamboogle and MuSiQue datasets
Breakthrough Assessment
8/10
Significant for demonstrating that process-level supervision derived from MCTS is far more data-efficient than outcome-based RL for agentic RAG, achieving better results with ~5% of the training data volume.