📊 Experiments & Results
Evaluation Setup
Zero-shot and Fine-tuned Video QA across varying video lengths and types
Benchmarks:
- PerceptionTest (General Video QA)
- NextQA (Causal/Temporal QA)
- ActivityNet-QA (Long-form QA)
- VideoMME (Comprehensive Video Understanding)
- MVBench (Fine-grained temporal understanding)
- Video-TT (Long-form understanding)
- ScanQA (Spatial scene understanding)
Metrics:
- Accuracy (%)
- Score (0-5 or 0-100 depending on benchmark)
- Time-to-first-token (TTFT)
- Token count
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison against the direct baseline LLaVA-Video-7B shows CoPE-VideoLM achieving higher accuracy with significantly fewer tokens. | ||||
| PerceptionTest | Accuracy | 62.4 | 69.3 | +6.9 |
| NextQA | Accuracy | 78.4 | 79.7 | +1.3 |
| Efficiency metrics demonstrate the drastic reduction in computational cost. | ||||
| Inference Latency | Time-to-first-token (TTFT) reduction | 0.0 | 86.2 | 86.2 |
| Inference Cost | Token usage reduction | 0.0 | 93.0 | 93.0 |
| Long-form video understanding results show scalability to extended contexts. | ||||
| Video-TT | Score | 59.3 | 64.5 | +5.2 |
| Video-MMMU | Score | 47.7 | 50.1 | +2.4 |
Experiment Figures
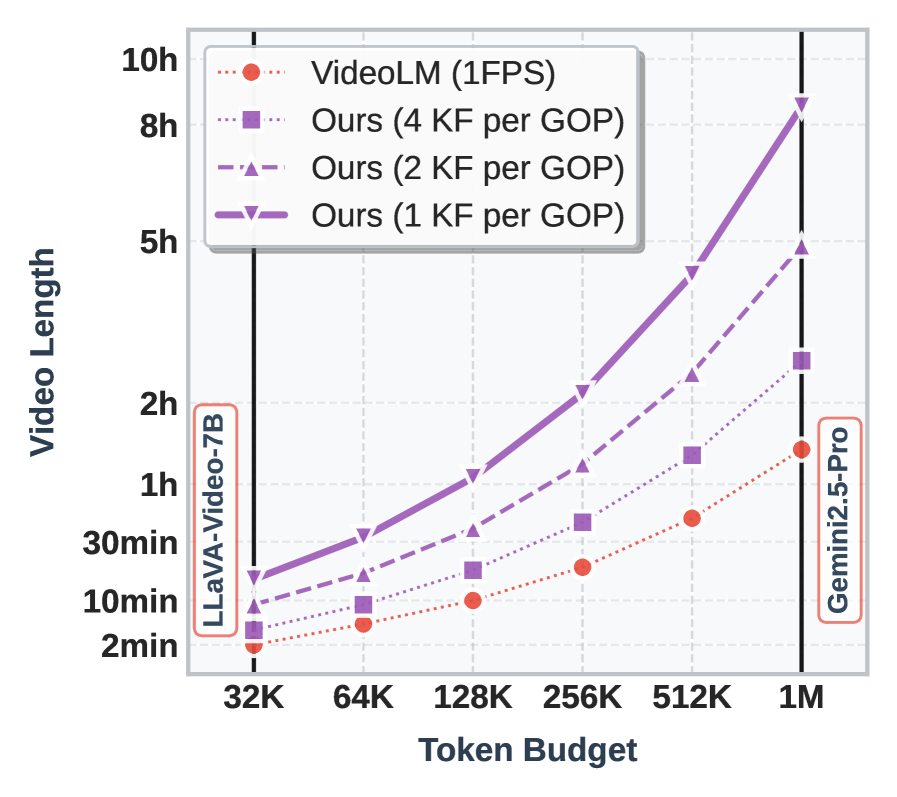
Scalability plot: Maximum video duration (hours) vs. Token Budget (M tokens) for different methods.
Main Takeaways
- Codec primitives (motion/residuals) are a highly effective substitute for dense RGB frames, preserving necessary information for complex reasoning while shedding massive redundancy.
- The approach scales much better than RGB baselines: token usage grows slowly, allowing 8-hour videos to fit in context windows that normally hold only minutes of dense video.
- Performance improvements are consistent across general QA, temporal reasoning, and long-form tasks, suggesting the delta-tokens capture robust semantic features.
- Pre-training the Delta-Encoder to align with the image encoder's space is a crucial step for effective integration into the VideoLM.