📝 Paper Summary
Modularized RAG pipeline
IRB automates the creation of RAG benchmarks by using human-written Wikipedia citations as a factual scaffold and knowledge graphs as an algorithmic scaffold to generate controlled, verifiable, and complex question-answer pairs.
Core Problem
RAG benchmarks suffer from rapid saturation and data contamination as newer models memorize web-scale data, while manual benchmark creation is expensive and pure LLM-generation lacks control and grounding.
Why it matters:
- Frontier models often memorize existing static benchmarks, making it impossible to distinguish between parametric knowledge and actual retrieval capabilities
- Fully automated generation approaches without explicit grounding often produce unfaithful samples or lack control over question complexity (e.g., multi-hop reasoning)
- Maintaining robust benchmarks requires constant, labor-intensive updates to include fresh data that models haven't seen during training
Concrete Example:
A purely neural generator might hallucinate a plausible-sounding but false fact. IRB avoids this by extracting a sentence like 'X won Y award in 2024' directly from Wikipedia, verifying the cited URL supports it, and then programmatically transforming it into a multi-hop question via a knowledge graph.
Key Novelty
Factual and Algorithmic Scaffolding for Benchmark Generation
- Uses 'factual scaffold': Extracts facts from human-written Wikipedia sentences with citations, treating the cited URLs as ground-truth evidence to ensure grounding
- Uses 'algorithmic scaffold': Converts facts into intermediate knowledge graphs to programmatically control question complexity (single-hop, multi-hop, false-premise) and prevent trivial generation
Architecture
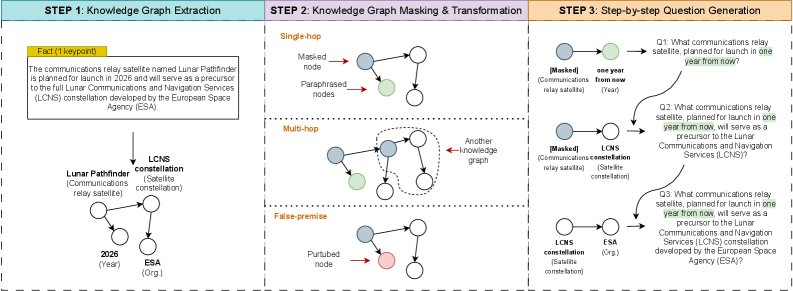
The automated question generation pipeline of IRB
Evaluation Highlights
- Generated IRB1K benchmark containing 1,000 questions from 2024-2025 Wikipedia articles, challenging frontier models significantly in closed-book settings
- Retrieval acts as an 'equalizer': The performance gap between top and bottom models shrinks by ~4x when retrieval is enabled compared to closed-book
- Reasoning models (e.g., GPT-5, DeepSeek-R1) show superior reliability in adversarial settings, such as handling false-premise questions and incorrect retrieval contexts
Breakthrough Assessment
8/10
Offers a scalable, controlled solution to the critical problem of benchmark contamination. The dual-scaffold approach balances automation with rigorous factual grounding.