📝 Paper Summary
LLM Knowledge Distillation
Privacy and Memorization in LLMs
Knowledge distillation acts as a strong regularizer that significantly reduces training data memorization compared to standard fine-tuning, while preferentially retaining 'easy-to-memorize' examples with low entropy.
Core Problem
While memorization is well-studied in standard pre-training and fine-tuning, its dynamics during knowledge distillation—where a student mimics a teacher's distribution—are poorly understood.
Why it matters:
- Large teacher models inevitably memorize training data, raising concerns that distilled students might inherit sensitive information or privacy vulnerabilities
- Distillation is often cited as a privacy defense, but the extent of data leakage remains unquantified in modern LLM settings
- Training data extraction attacks can recover proprietary or private data, so understanding defense mechanisms is crucial for safe deployment
Concrete Example:
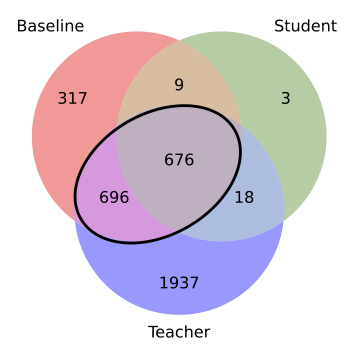
A baseline 1.4B model fine-tuned on FineWeb memorizes 1,698 specific training examples. When the same 1.4B model is trained via distillation from a 12B teacher on the same data, it memorizes only ~700 examples, rejecting over 50% of the memorization risks.
Key Novelty
Distillation as a Memorization Filter
- Demonstrates that minimizing KL divergence (soft targets) acts as a regularizer, preventing the student from over-fitting to specific training examples compared to cross-entropy (hard targets)
- Identifies 'easy-to-memorize' examples (low zlib entropy, low perplexity) that are deterministically memorized across models, while harder examples are filtered out by distillation
- Proposes a pre-distillation classifier that uses teacher/baseline statistics to predict and remove high-risk memorization candidates before training begins
Architecture
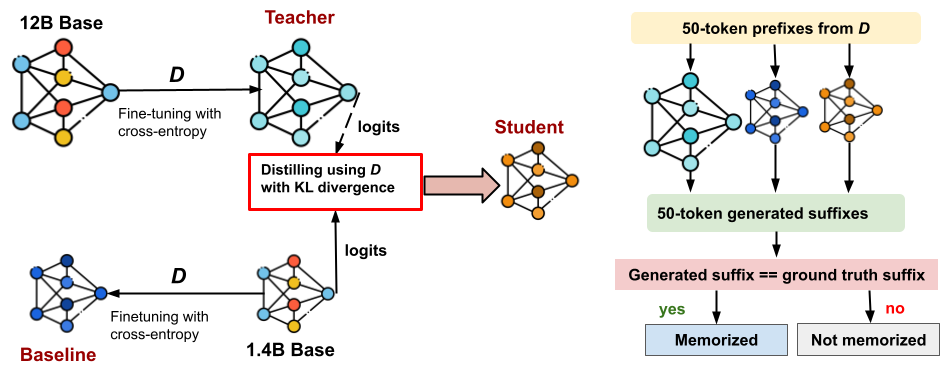
Experimental framework comparing three training setups: Teacher (Cross-Entropy), Baseline (Cross-Entropy), and Student (KL Divergence Distillation), followed by a Memorization Evaluation phase.
Evaluation Highlights
- Distilled Pythia-1.4B student reduces memorization by ~2.4x compared to a standard fine-tuned baseline on FineWeb data (from ~1700 to ~700 examples)
- Student inherits only 0.9% (18 out of 1,955) of the examples exclusively memorized by the Teacher, effectively stripping unique teacher-side risks
- A logistic regression classifier predicts student memorization with 0.9997 AUC prior to training, enabling the removal of 99.8% of memorized examples
Breakthrough Assessment
7/10
Provides the first systematic quantification of memorization in LLM distillation. While methodologically straightforward, the finding that distillation is a robust privacy defense (reducing memorization by >50%) is highly significant.