📝 Paper Summary
Factuality evaluation
Medical Knowledge Graphs (KGs)
FAITH is an unsupervised, reference-free framework that evaluates the factuality of medical LLM responses by decomposing them into atomic claims and verifying them against paths in a medical knowledge graph.
Core Problem
Deploying LLMs in healthcare requires rigorous factuality verification, but traditional metrics like BLEU require reference answers (often unavailable) and correlate poorly with clinician judgments of factual accuracy.
Why it matters:
- LLMs frequently produce plausible but dangerously inaccurate medical information (hallucinations), undermining trust and patient safety
- Clinical studies are too slow to keep pace with LLM development, necessitating automated evaluation methods
- Existing model-based evaluators (LLM-as-a-judge) are themselves prone to hallucinations and lack explainability regarding why a claim is rejected
Concrete Example:
An LLM might claim 'dry cough is a symptom of bronchiectasis'. Traditional metrics check lexical overlap with a reference, ignoring the specific medical fact. FAITH extracts this claim, maps 'dry cough' and 'bronchiectasis' to KG nodes, and verifies if a valid evidence path exists between them.
Key Novelty
Knowledge Graph-Grounded Reference-Free Evaluation
- Decomposes text into atomic claims and maps entities to a standard medical ontology (UMLS) rather than relying on text overlap or another LLM's opinion
- Scores factuality by finding the shortest path between entities in the KG and assessing the semantic congruence of the path's relations to the claim's predicate
- Incorporates entity centrality (PageRank) and relationship co-occurrence patterns to penalize generic or weak associations
Architecture
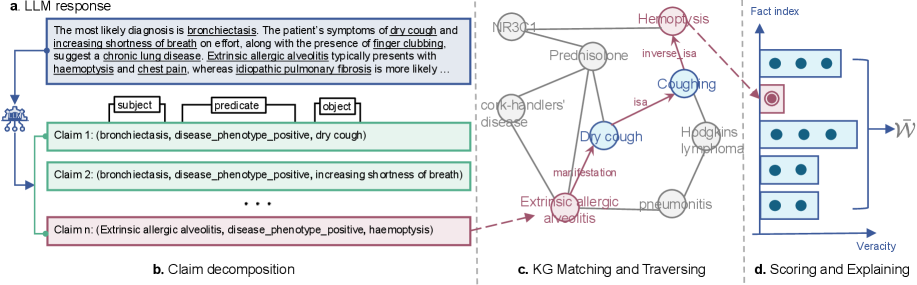
The complete FAITH pipeline, illustrating the process from an LLM response to a final factuality score using a Knowledge Graph.
Evaluation Highlights
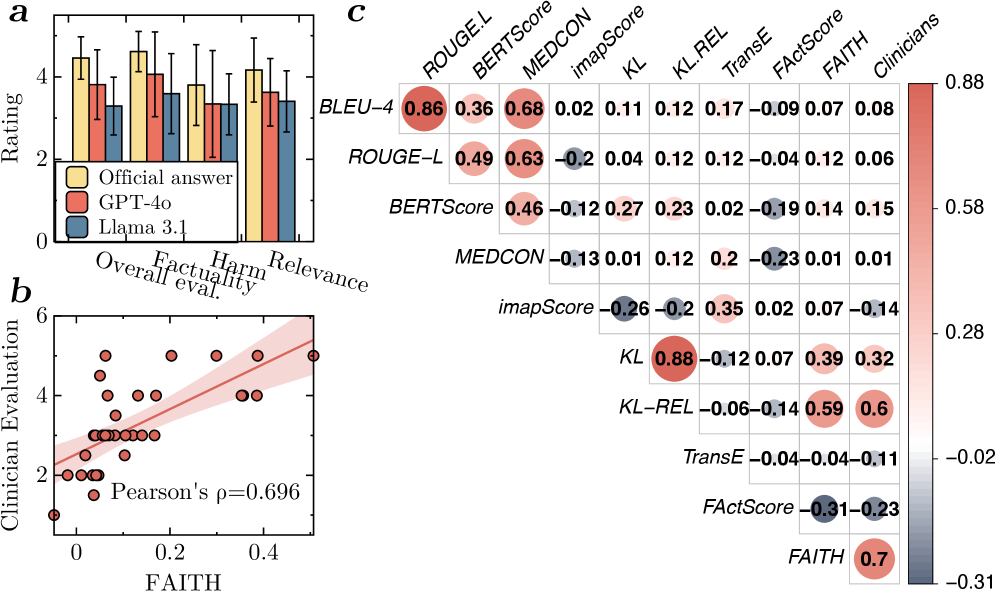
- Achieves Pearson correlation of 0.696 with human clinician judgments, significantly outperforming BLEU-4 (0.081) and GPT-4o-based metrics
- Robust to paraphrasing with a coefficient of variation of 0.014 ± 0.005, compared to 0.910 ± 0.862 for BLEU-4
- Pinpoints erroneous statements identified by clinicians with a precision of 0.65 and recall of 0.59
Breakthrough Assessment
8/10
Significant improvement in correlation with human experts for medical fact-checking without needing reference answers. The approach offers high explainability, though it relies heavily on the completeness of the underlying Knowledge Graph.