📝 Paper Summary
Modularized RAG pipeline
Efficient Inference
FlashBack improves RAG inference speed by appending retrieved documents to the end of the context—avoiding KV cache recomputation—and using Marking Tokens with LoRA to recover model performance.
Core Problem
Standard In-Context RALM prepends retrieved documents to the input, forcing the model to discard and recompute the Key-Value (KV) cache for the entire context every time the retrieved content changes.
Why it matters:
- Recomputing the KV cache for long contexts is computationally expensive, growing quadratically with sequence length
- High inference latency hinders the deployment of Retrieval-Augmented Language Models (RALM) in real-time applications
- Existing methods effectively utilize off-the-shelf LLMs but suffer from this inefficiency when performing frequent retrieval during generation
Concrete Example:
In a standard setup, if an LLM has processed a 2000-token prompt and then retrieves new documents, prepending those documents invalidates the cache for all 2000 tokens, forcing a full re-process. FlashBack appends the documents, keeping the 2000-token cache valid.
Key Novelty
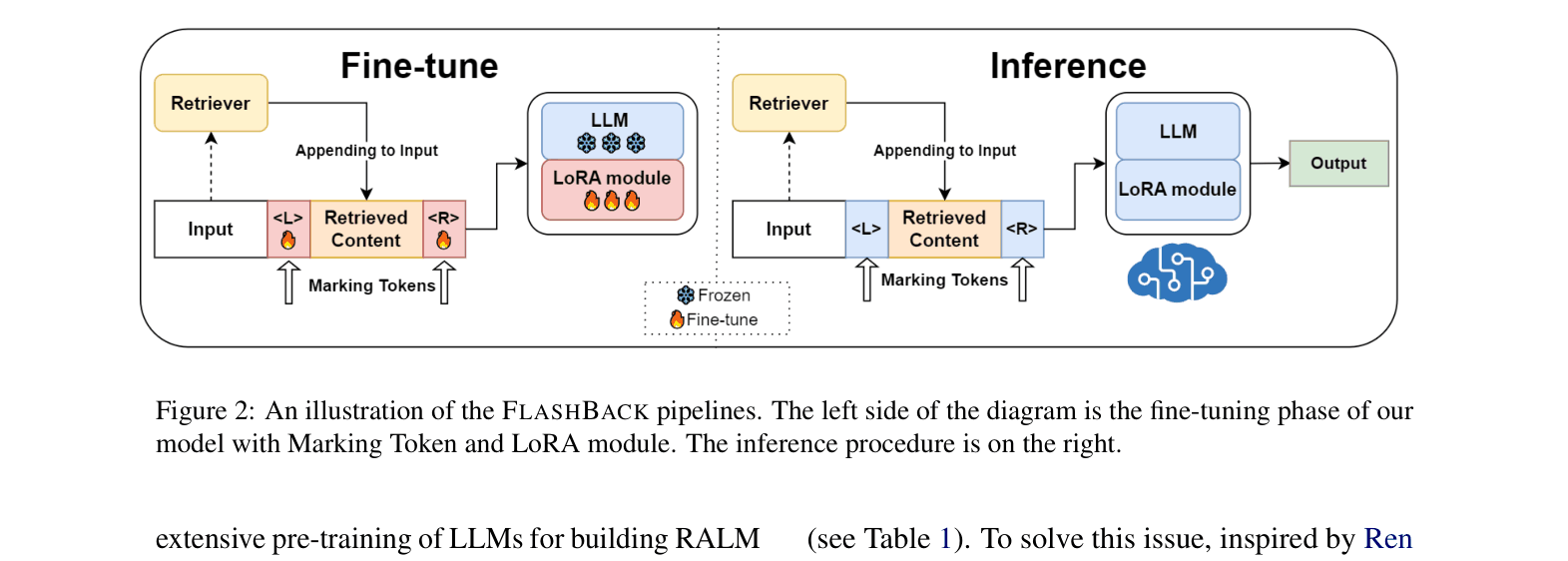
Appending Context Pattern with Marking Tokens
- Shift retrieved documents from the beginning (prepending) to the end (appending) of the context to preserve the static KV cache of the input prompt
- Introduce learnable 'Marking Tokens' (<MARK_L>, <MARK_R>) to demarcate appended content, helping the model distinguish between user input and retrieved data
- Use Low-Rank Adaptation (LoRA) to fine-tune only the attention layers and marking tokens, adapting the frozen LLM to this new unnatural context pattern
Architecture
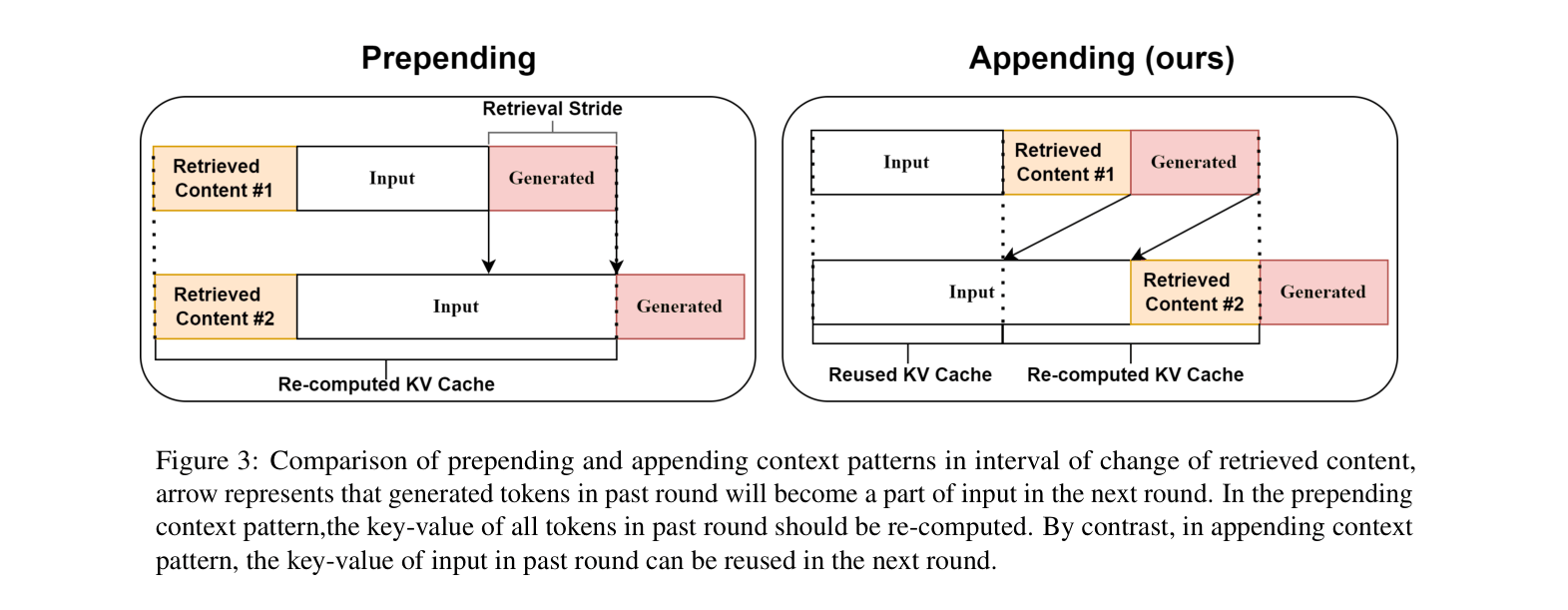
Contrast between Prepending and Appending context patterns regarding KV cache reuse
Evaluation Highlights
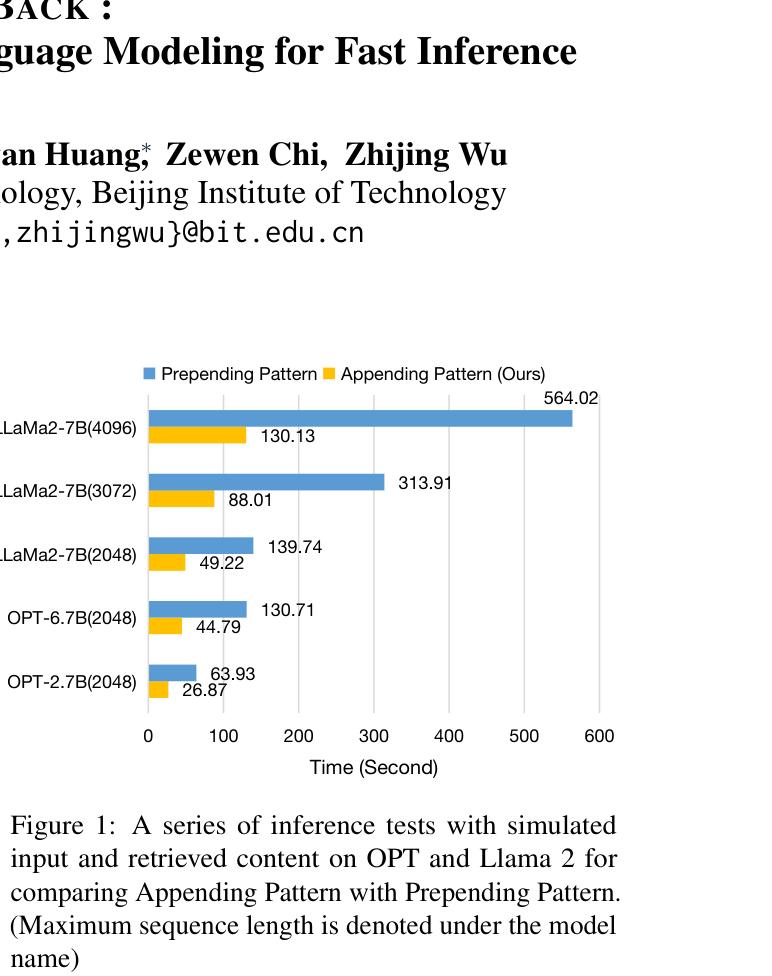
- Achieves up to 4x faster inference speed on Llama 2 (7B) compared to the prepending baseline
- Maintains comparable perplexity (PPL) to full-context prepending methods after fine-tuning (e.g., 9.40 PPL vs 10.70 baseline on WikiText-2 for OPT-6.7B)
- Marking Tokens explicitly improve downstream Question Answering performance (20.3 vs 18.7 EM on Natural Questions for OPT-6.7B)
Breakthrough Assessment
7/10
Simple yet highly effective architectural shift for efficiency. Solves a major RAG bottleneck (KV recomputation) with minimal performance trade-offs, though relies on established techniques (LoRA).