📝 Paper Summary
Data Selection
Data Curation
The paper proposes a multi-actor framework where independent data selection 'actors' (Quality, Domain, Topic) collaborate via a central console that dynamically adjusts their influence based on model feedback, optimizing data efficiency and performance.
Core Problem
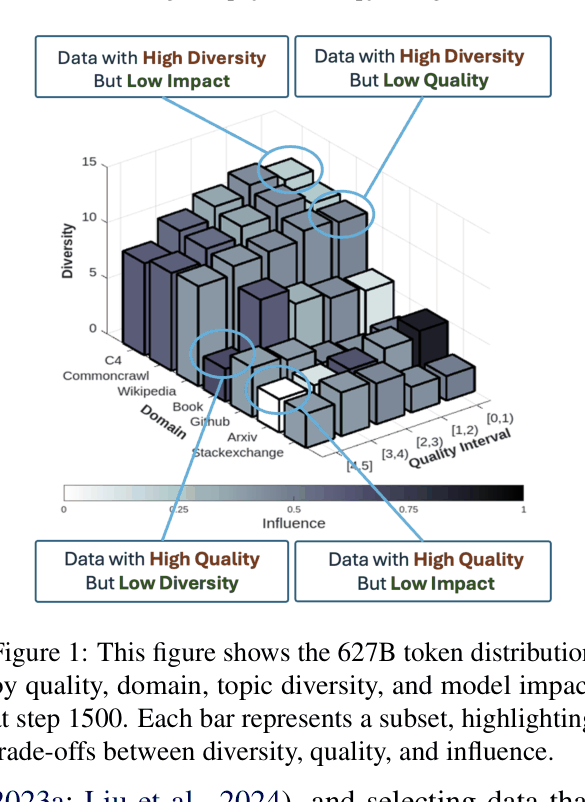
Existing data selection methods (quality filtering, domain mixing, influence functions) often conflict with each other (e.g., high-quality data might have low topic diversity or low model influence), and integrating them naively is inefficient or leads to suboptimal results.
Why it matters:
- Data quality significantly impacts LM performance and training efficiency.
- Online selection methods like MATES or DSDM are computationally expensive (require relabeling entire datasets frequently).
- Static heuristics don't adapt to the model's evolving state during training.
Key Novelty
Multi-Actor Collaborative Data Selection
- Decomposes data selection into separate 'Actors' (e.g., Quality Actor, Domain Actor, Topic Actor), each maintaining its own memory and scoring logic.
- Uses an 'Actor Console' to dynamically aggregate scores from actors and adjust their weights (collaboration) based on reward signals (influence functions on reference tasks) from the current model state.
- Combines offline labeling (cheap) with online weight updates (adaptive) to balance efficiency and performance.
Architecture
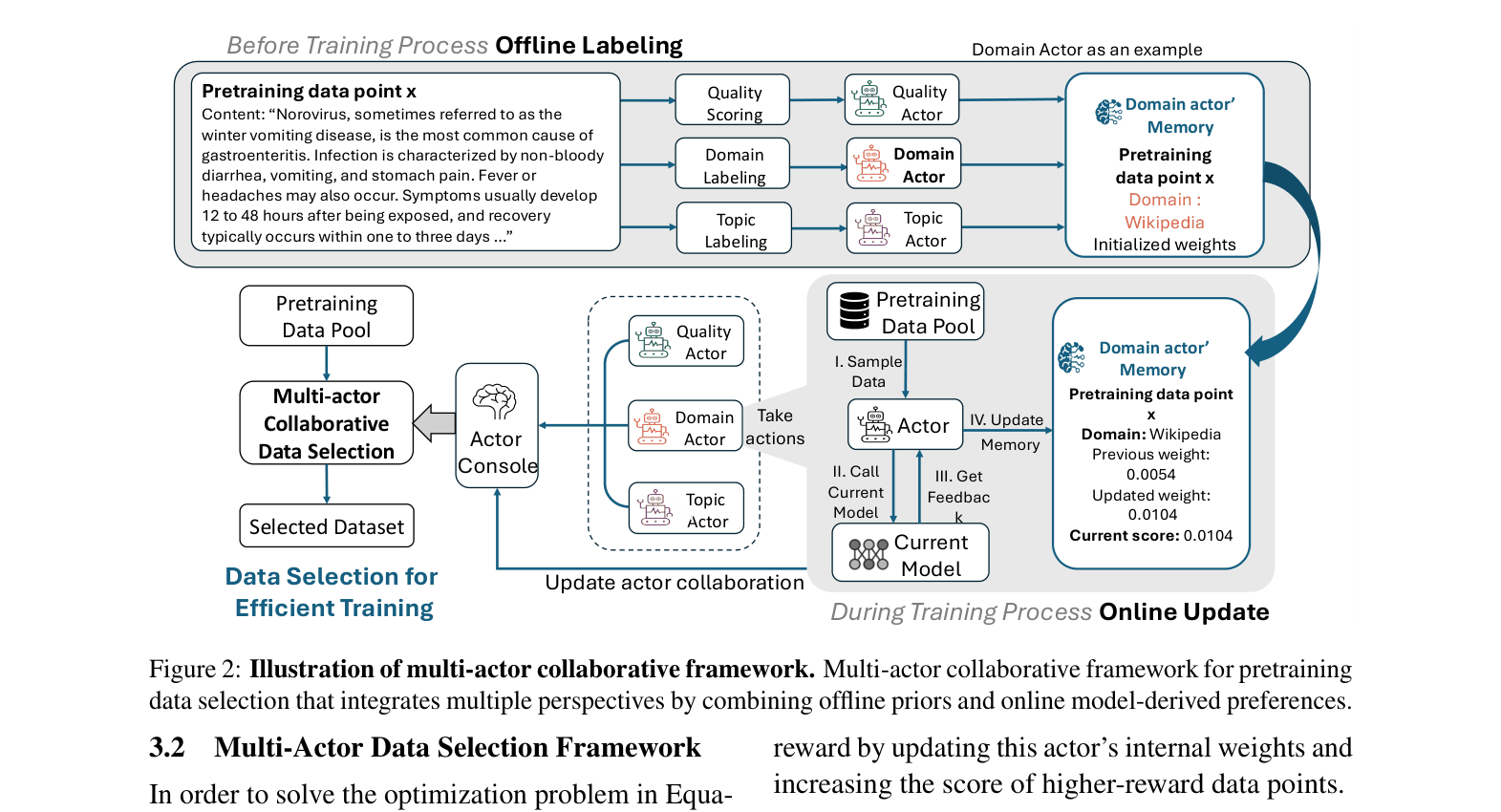
The multi-actor collaborative framework. It shows the offline labeling phase and the online loop where the Actor Console aggregates scores from Quality, Domain, and Topic actors, gets feedback from the model, and updates actor weights.
Evaluation Highlights
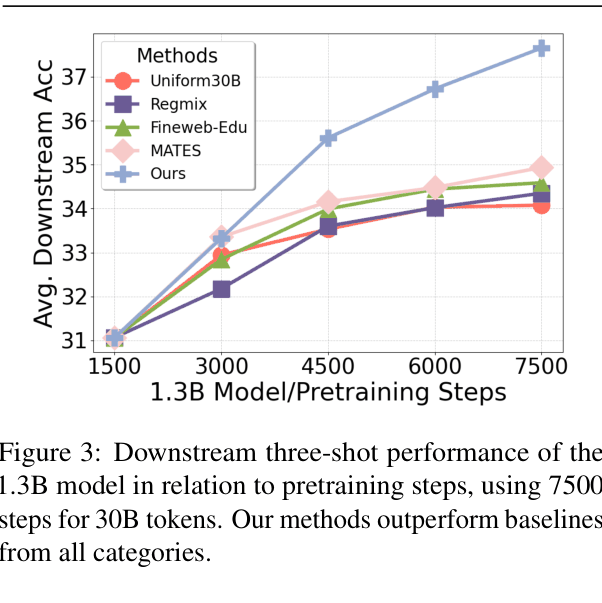
- Achieves up to 10.5% relative performance gain on average across benchmarks compared to state-of-the-art baselines (including MATES, DoReMi, QuRating).
- Significantly improves data efficiency: A 30B token run outperforms a 60B token random sampling baseline.
- Reduces computational cost: 1/7th the FLOPs of QuRating and half the FLOPs of MATES.
Breakthrough Assessment
7/10
The method effectively solves the conflict between different data selection heuristics and scales well. The performance gains (+10.5% avg) and efficiency improvements over strong baselines like MATES make it a significant contribution to pretraining science.