📝 Paper Summary
Language Model Pretraining
Hierarchical Representation Learning
ConceptLM improves language models by adding a Next Concept Prediction objective that quantizes token sequences into discrete high-level concepts and predicts them alongside standard tokens.
Core Problem
Standard Next Token Prediction (NTP) focuses on low-level units, failing to fully utilize model capacity for high-level abstraction and long-range planning as models scale up.
Why it matters:
- Current LLMs are constrained to token-level prediction despite trillion-parameter scales, potentially bottlenecking their ability to model complex reasoning or global dependencies.
- Existing hierarchical models often still rely on token/byte-level objectives or implicit representations without explicit supervision for high-level planning.
- Predicting only the next immediate token discourages models from learning broader semantic trajectories essential for coherent long-form generation.
Concrete Example:
In a long narrative, a token-level model might predict the word 'bank' based on local context like 'walked to the', whereas a concept-level model predicts the abstract concept of 'financial institution' or 'river side' based on the entire preceding paragraph, guiding the subsequent token generation more effectively.
Key Novelty
Next Concept Prediction (NCP)
- Constructs a discrete 'concept vocabulary' by grouping multiple tokens into a single hidden state and quantizing it using a codebook.
- Simultaneously predicts the next high-level concept (spanning k tokens) and the next low-level tokens, essentially planning the future semantic content before generating the specific words.
- Uses the predicted concept embedding to condition the generation of the subsequent tokens, creating a top-down guidance mechanism.
Architecture
Overview of the ConceptLM architecture demonstrating the parallel concept and token processing streams.
Evaluation Highlights
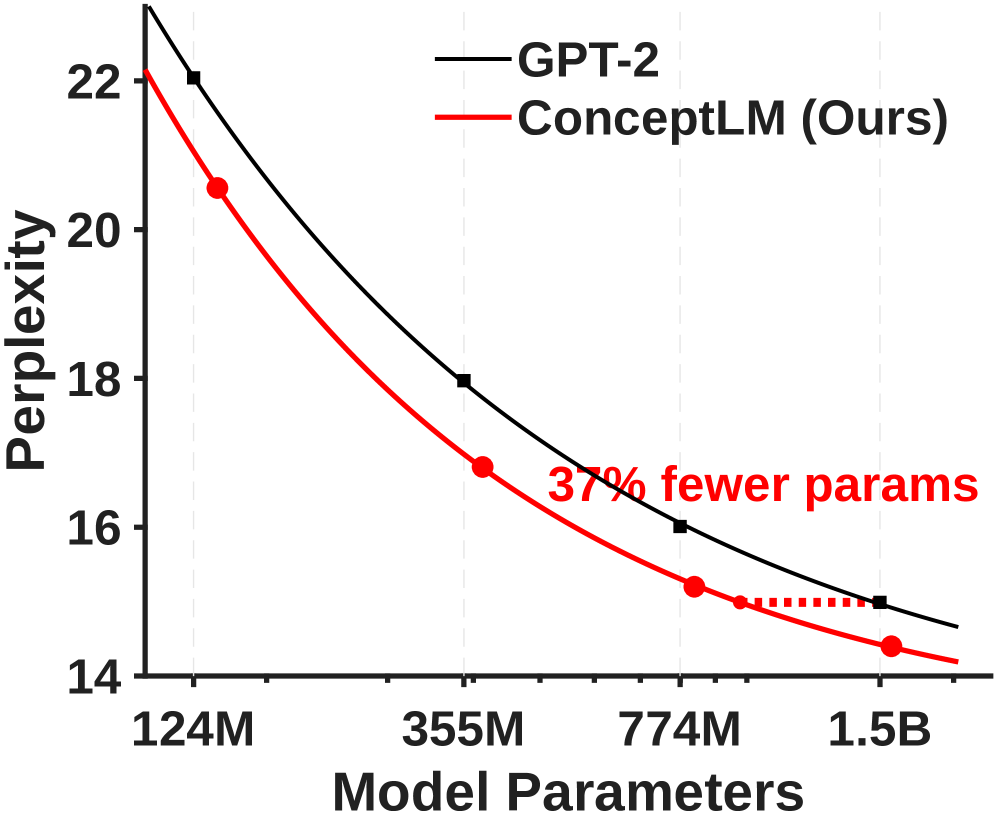
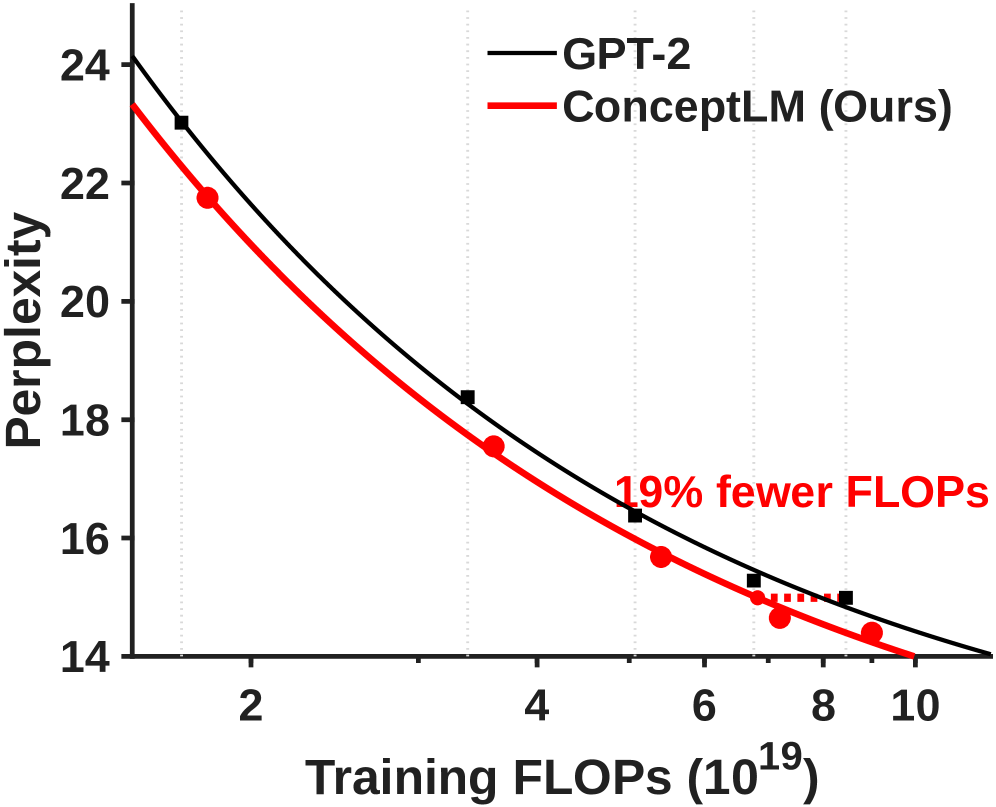
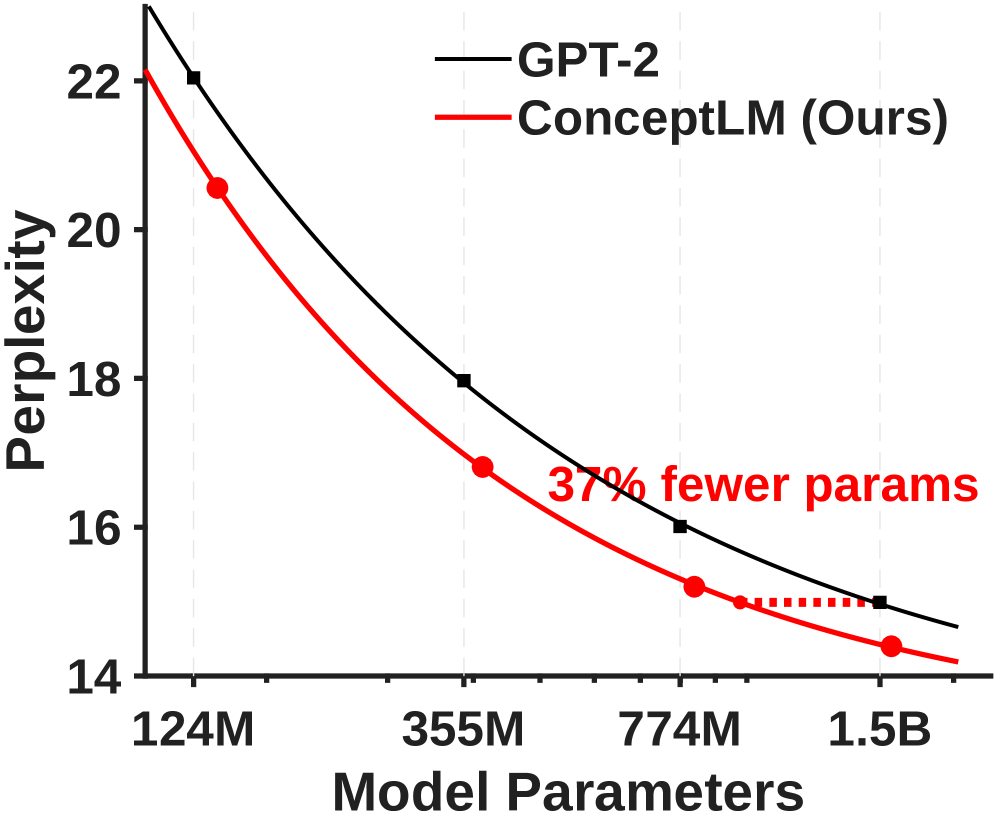
- Achieves comparable performance to a 1.5B parameter GPT-2 baseline using only 63% of the parameters (950M) or 76% of the training tokens.
- Continual pre-training of Llama-3.1-8B with NCP for just 9.6B tokens yields a +0.4 average score improvement across 4 benchmarks (MMLU, ARC-C, AGIEval, SQuAD) compared to a token-level baseline.
- Outperforms standard Pythia baselines on 9 downstream tasks (average accuracy) across scales from 70M to 410M parameters.
Breakthrough Assessment
8/10
Offers a practical, scalable implementation of hierarchical prediction that actually improves downstream performance and scaling laws, a long-standing goal in LM research that often fails in practice.