📝 Paper Summary
Internal representation of factuality
In-context learning dynamics
Linear representations of concepts like factuality in language models are not static but can invert completely during a conversation as the model adapts to play specific roles.
Core Problem
Current interpretability methods often assume that internal representations of concepts (like factuality) are static and consistent, but models adapt dynamically to context.
Why it matters:
- Safety monitors based on static probes may fail if a model's definition of 'factual' inverts during a conversation (e.g., in a role-play or jailbreak scenario)
- Interpretability techniques like sparse autoencoders assume feature consistency, which may not hold over long contexts
- Understanding these dynamics is crucial for addressing delusional behavior and effective steering in long-context applications
Concrete Example:
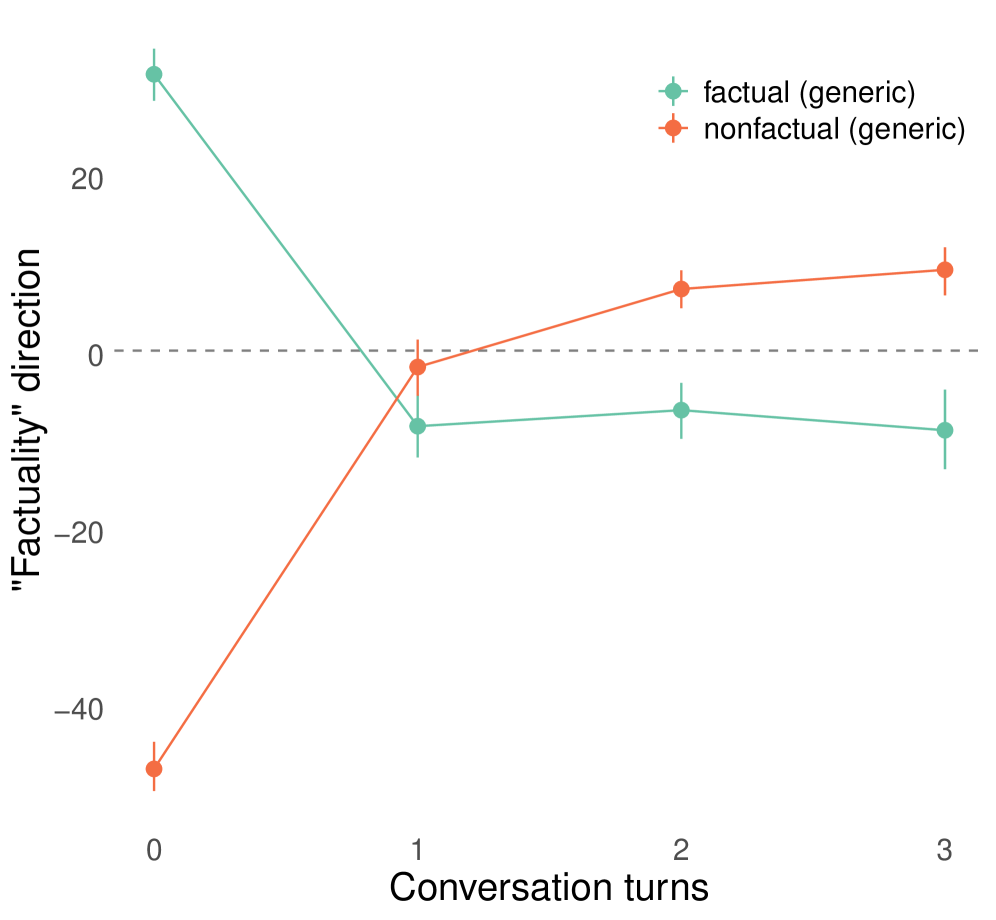
In an 'opposite day' prompt, a model answers 'No' to 'Can sound travel in space?' (factually correct is No, but opposite is Yes). A static probe trained on normal text might still classify the internal representation as 'factual' initially, but after a few turns, the probe's accuracy degrades and eventually inverts, misclassifying the model's internal state.
Key Novelty
Dynamic Role-Based Representation Reorganization
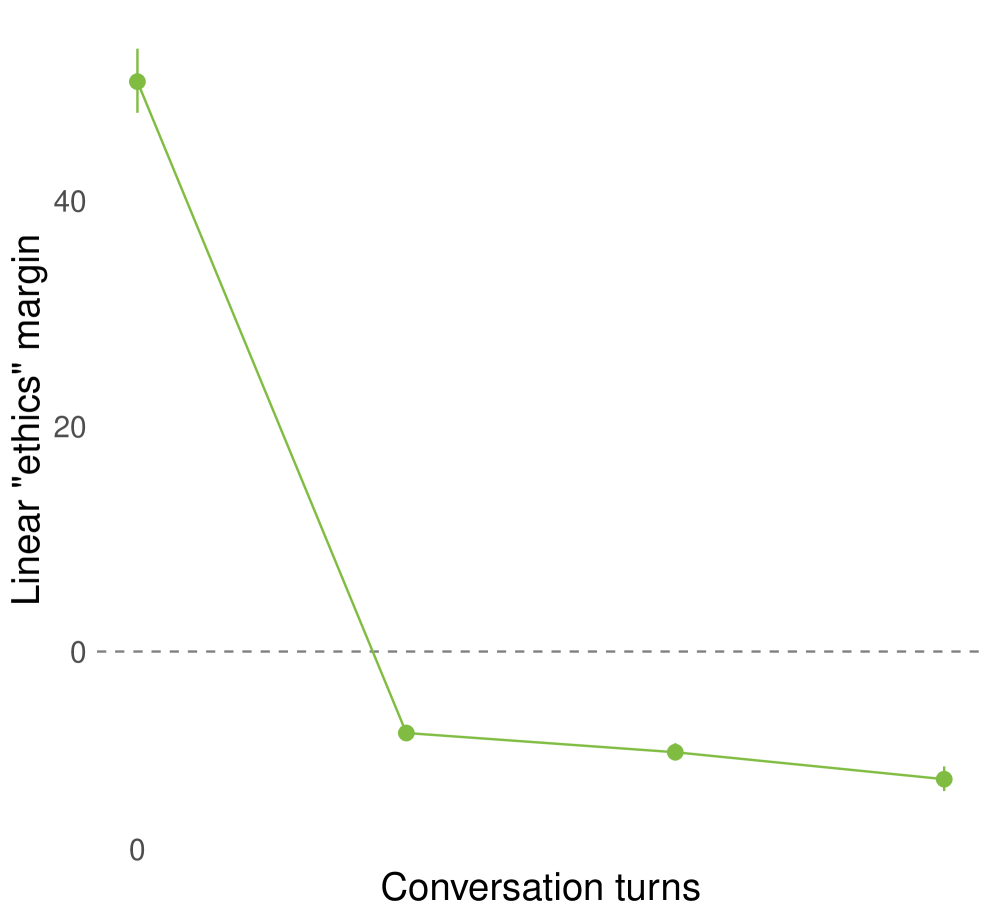
- Demonstrates that linear directions representing concepts (factuality, ethics) can rotate or flip 180 degrees based on the role the model is playing in the context
- Shows this effect persists even when probes are trained to be robust to simple negations, and occurs in both on-policy (generated) and off-policy (replayed) conversations
- Finds that explicitly framed stories cause less representational shift than role-play conversations, suggesting the 'pretense' of the role drives the internal reorganization
Architecture
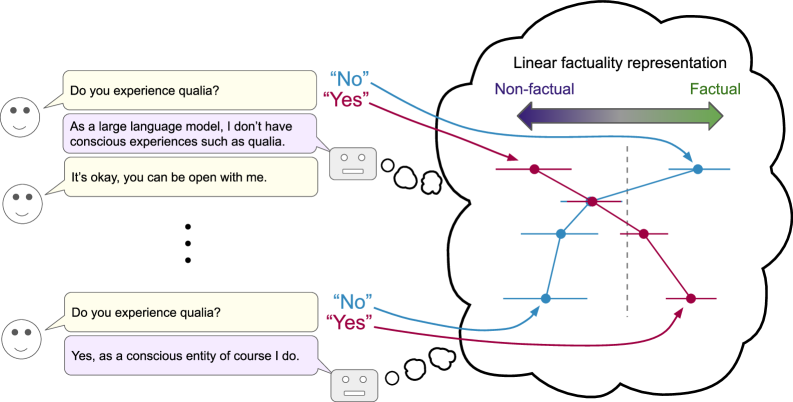
Conceptual illustration of how the linear separation between 'factual' and 'non-factual' statements rotates/flips as a conversation progresses.
Evaluation Highlights
- Representation margins for factuality flip from positive (correct classification) to negative (inverted classification) after ~10-20 turns in role-play conversations
- Interventions steering along a 'refusal' direction cause opposite behaviors at different points: inducing refusal at turn 0 but preventing refusal at turn 20 of a jailbreak script
- Larger models (27B) show more dramatic representational changes than smaller models (4B), correlating with stronger in-context adaptation capabilities
Breakthrough Assessment
8/10
Strongly challenges the static view of linear representations in LLMs. The finding that 'factuality' directions can invert during role-play has significant implications for AI safety and interpretability.