📝 Paper Summary
Memory organization
Agentic AI
Long-context reasoning
StateLM empowers language models to actively manage their own context window by learning to selectively preserve insights in notes and delete redundant raw text during long-horizon reasoning.
Core Problem
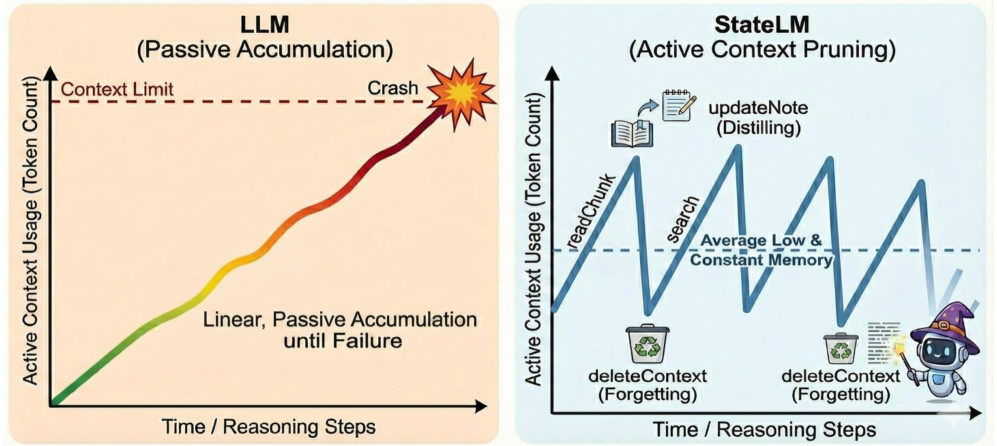
Standard LLMs are passive predictors that accumulate context monotonically, leading to context exhaustion and performance degradation in long tasks because they cannot actively manage their memory.
Why it matters:
- Current approaches rely on brittle 'Context Engineering' where humans manually script what information is fed to the model, limiting the model's agency.
- Monotonic context growth eventually hits fixed window limits, causing failure in tasks like deep research or reading full novels.
- Existing solutions focus on external retrieval systems (the 'Pensieve') but leave the model without the ability (the 'wand') to autonomously decide what to keep or discard.
Concrete Example:
In a deep research task, a standard model reads dozens of web pages, filling its context window with raw HTML until it crashes or hallucinates. StateLM, conversely, reads a page, summarizes key facts into a note, and immediately deletes the raw page from its context, keeping the memory buffer small and relevant.
Key Novelty
The Pensieve Paradigm (Self-Context Engineering)
- Equips the model with a 'deleteContext' tool, allowing it to remove specific past messages or observations from its own visible history.
- Maintains a 'sawtooth' context profile: the context grows as data is read, then shrinks as the model distills information into notes and deletes the raw source.
- Transforms the model from a passive token accumulator into a state-aware agent that actively curates its working memory loop (Search → Read → Note → Delete).
Architecture
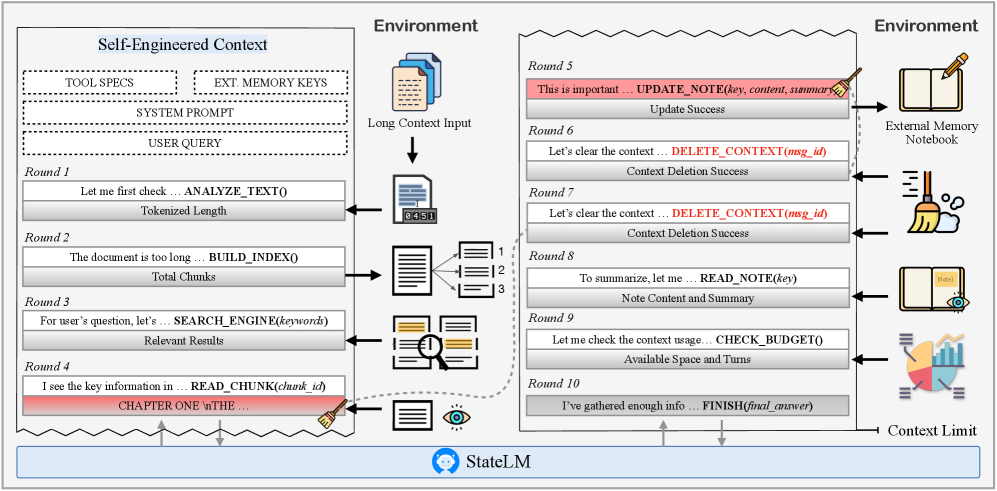
The StateLM reasoning flow showing the interaction between the model and its memory tools.
Evaluation Highlights
- Achieves up to 52% accuracy on the BrowseComp-Plus deep research task, while standard LLMs struggle around 5% (an improvement of over 40%).
- Outperforms standard LLMs on the chat memory task with absolute accuracy improvements of 10% to 20%.
- Maintains consistently higher accuracy on long-document QA benchmarks while using only ~25% of the active context compared to baselines.
Breakthrough Assessment
9/10
Introduces a fundamental shift from passive context accumulation to active, learned context pruning. The performance gap on complex tasks (5% vs 52%) is massive, suggesting a scalable solution to the finite context window problem.