📊 Experiments & Results
Evaluation Setup
Zero-shot reasoning across diverse domains
Benchmarks:
- BBH (General Reasoning)
- MMLU (General Knowledge/Reasoning)
- GSM8K (Math Word Problems)
- MATH (Challenging Math Problems)
- HumanEval (Code Generation)
- DROP (Reading Comprehension)
- PopQA (Question Answering)
- TruthfulQA (Question Answering)
- IFEval (Instruction Following)
Metrics:
- Accuracy (Exact Match or equivalent)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Overall performance comparison showing NRT's dominance across different model sizes. | ||||
| Average (9 benchmarks) | Score | 46.0 | 56.2 | +10.2 |
| Average (9 benchmarks) | Score | 50.8 | 56.2 | +5.4 |
| Average (9 benchmarks) | Score | 36.4 | 39.9 | +3.5 |
| Performance on specific challenging reasoning tasks (Math and General Reasoning). | ||||
| GSM8K | Accuracy | 29.0 | 76.0 | +47.0 |
| BBH | Accuracy | 41.2 | 54.3 | +13.1 |
| HumanEval | Pass@1 | 52.4 | 63.4 | +11.0 |
Experiment Figures
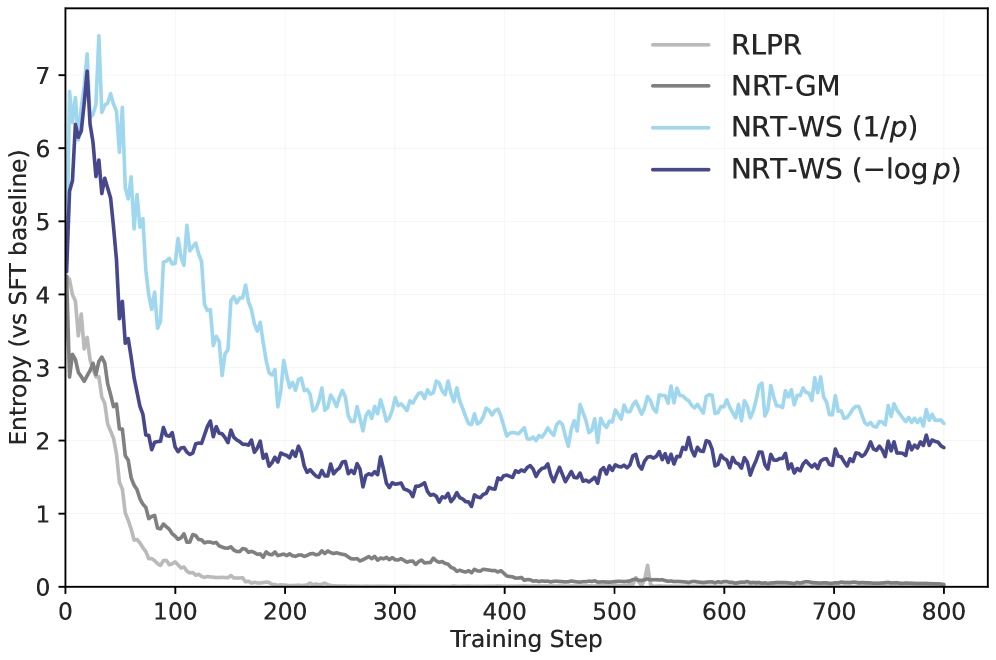
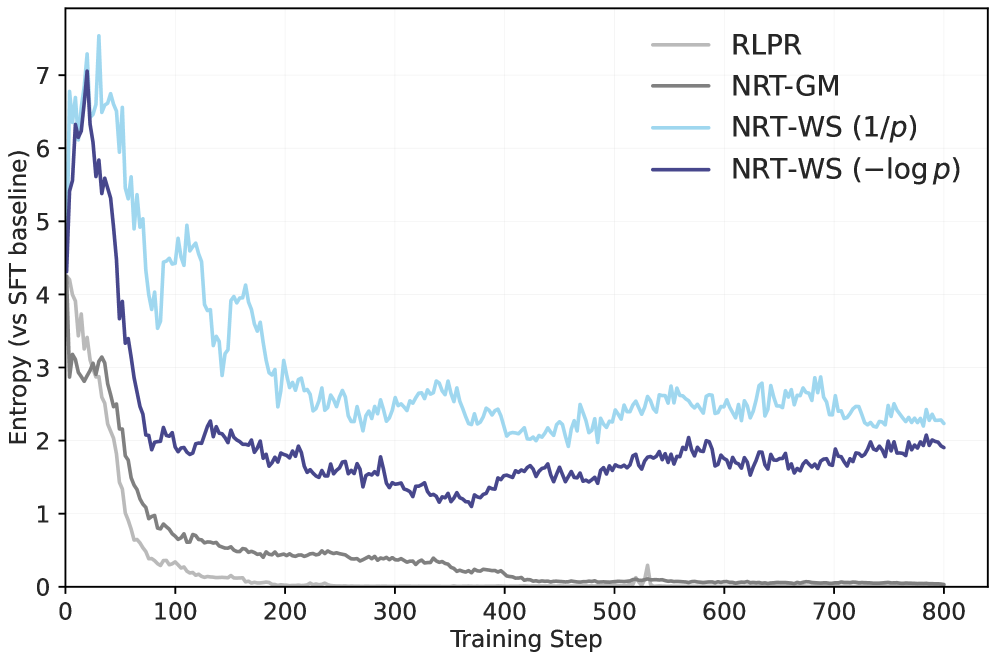
Evolution of reasoning trace metrics (entropy, length, quality) during training for RLPR vs NRT variants
Confidence improvement on answer tokens stratified by difficulty (baseline entropy)
Main Takeaways
- NRT consistently outperforms SFT and prior verifier-free RL methods across diverse benchmarks (Math, Coding, QA).
- Weighted Sum (WS) reward schemes focusing on difficult tokens are superior to Arithmetic Mean (RLPR) or Sequence Probability (JLB/Verifree) schemes.
- The method is robust to policy collapse: baselines like RLPR degrade into short, repetitive outputs, while NRT maintains long, high-entropy, and meaningful reasoning traces.
- Analysis of token probabilities shows NRT specifically improves confidence on 'hard' tokens (high entropy) where SFT struggles, confirming the reward shaping works as intended.