📝 Paper Summary
Data-centric AI
Vision-Language Pre-training
Synthetic Data Generation
A scalable pipeline generates ultra-detailed image captions by combining visual expert tools with LLM expansion, then refining them via human-corrected preference optimization and a critic-rewrite mechanism.
Core Problem
Existing image caption datasets for training Large Vision-Language Models (LVLMs) lack sufficient fine-grained details, limiting model capabilities in object attributes, relationships, and intricate visual reasoning.
Why it matters:
- Current datasets (COCO, LAION) are too brief, causing LVLMs to miss visual nuances and fail at complex reasoning tasks
- High-quality, detailed captions are essential for modality alignment but are scarce and expensive to annotate manually at scale
- Models trained on coarse data suffer from hallucinations and poor generalization in dense visual scenes
Concrete Example:
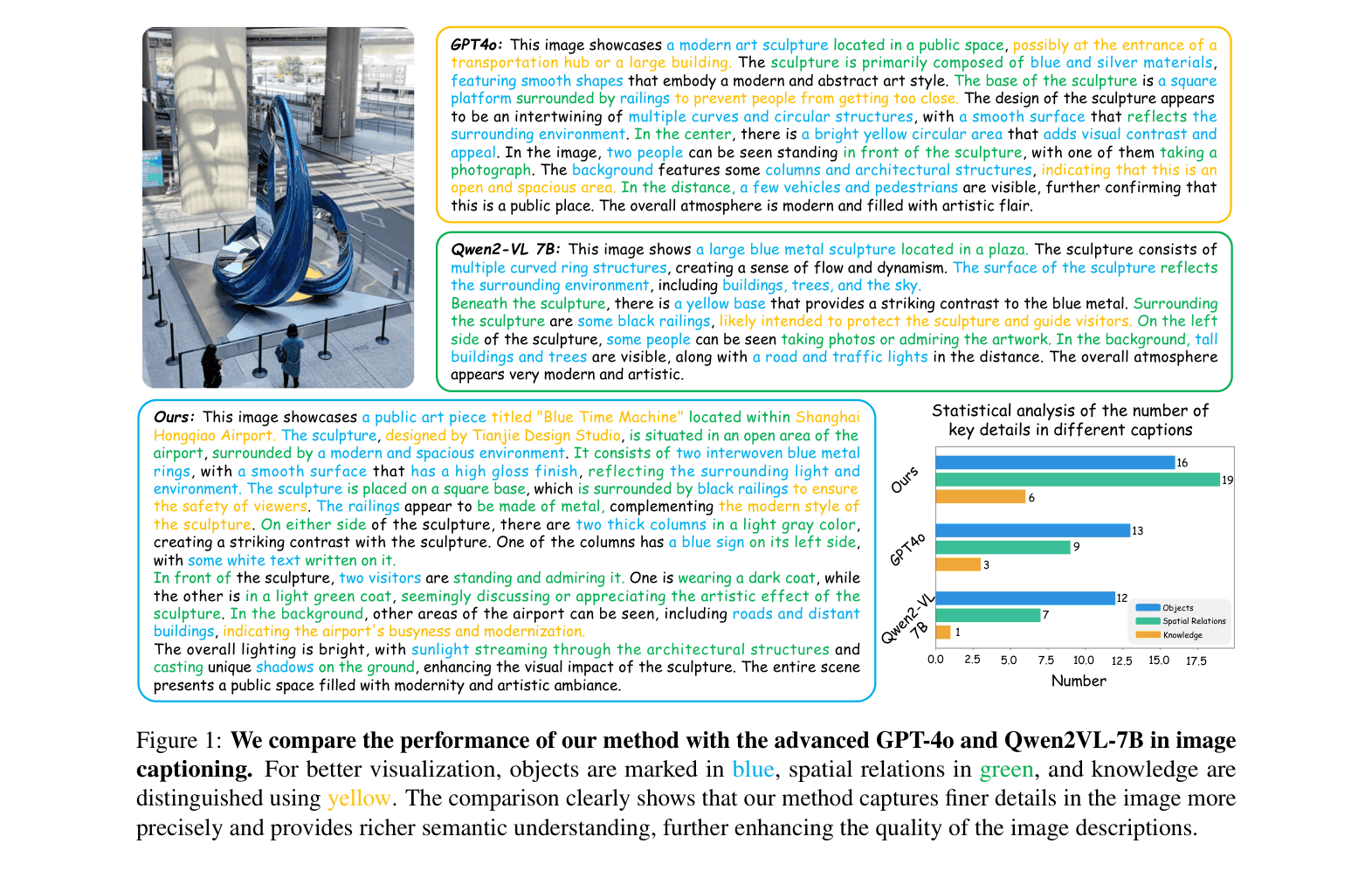
For an image of a sculpture, standard models might output 'A blue metal sculpture in a plaza.' The proposed method generates a paragraph detailing the 'interwoven blue metal rings,' 'high gloss finish reflecting light,' 'square base with black railings,' and 'visitors in dark and light green coats.'
Key Novelty
UltraCaption Pipeline
- Multi-stage generation: Uses visual expert tools (OCR, detection) to seed GPT-4o, then expands captions via LLM-driven prompts covering 8 descriptive dimensions
- Post-processing refinement: Trains a captioner using DPO (Direct Preference Optimization) on human-corrected data to fix hallucinations
- Fine-grained Critic: Decomposes captions into atomic sentences, critiques each using a learned model, and rewrites the final caption to maximize factual accuracy
Architecture
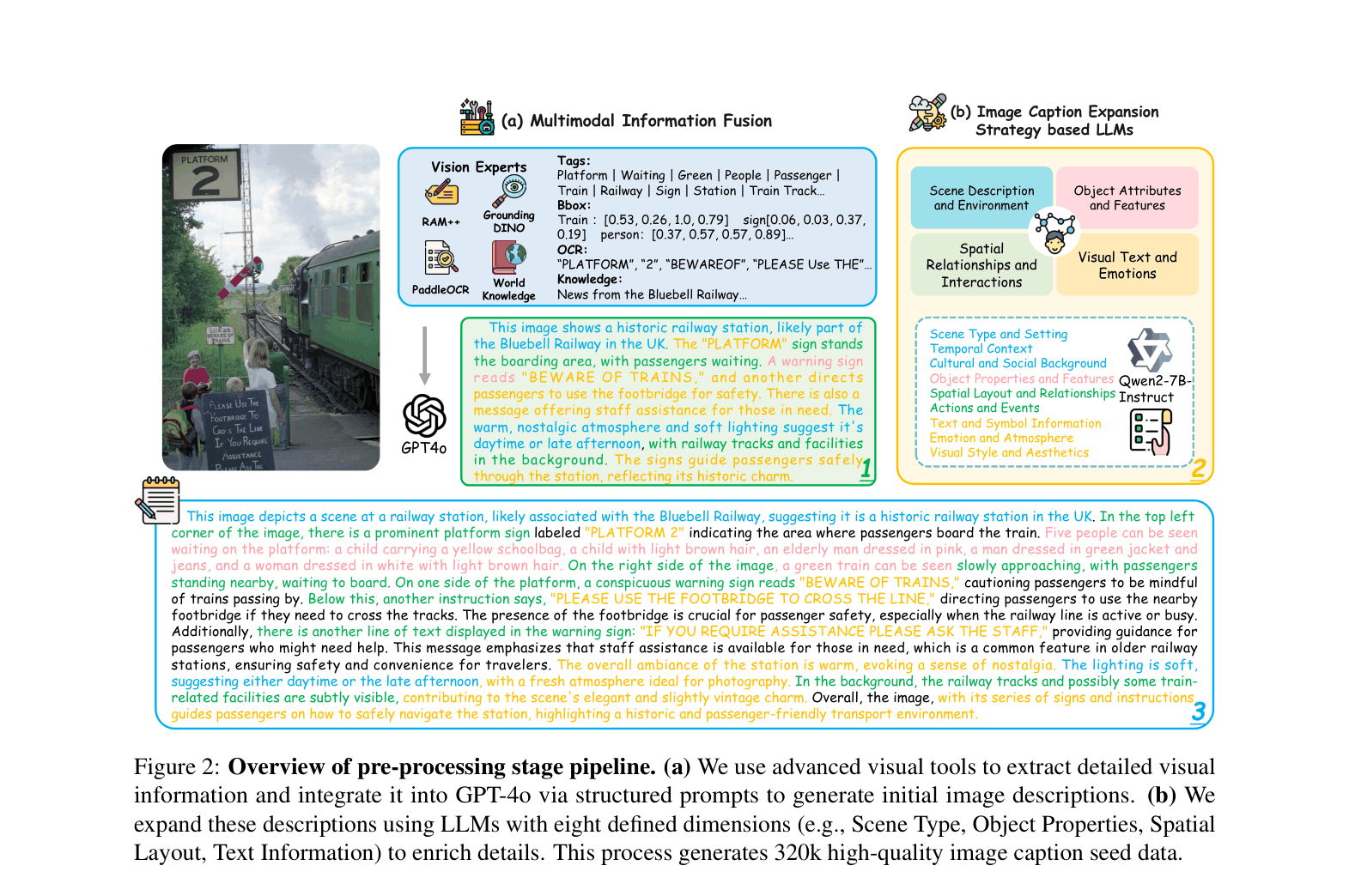
The complete two-stage pipeline: Pre-processing (Visual Tools -> GPT-4o -> LLM Expansion) and Post-processing (Human Correction -> DPO -> Critic-Rewrite).
Evaluation Highlights
- +3.4% accuracy improvement on MMBench-CN when training LLaVA-1.5 with the proposed data compared to standard training
- +13.1% accuracy gain on TextVQA (OCR-heavy task) for LLaVA-1.5, showing the benefit of incorporating specific OCR tools in the pipeline
- Outperforms ShareGPT4V-trained models on 7 out of 9 benchmarks, including reducing hallucination rates on POPE by +1.7%
Breakthrough Assessment
8/10
Offers a comprehensive, scalable solution to the data bottleneck in LVLMs. The combination of expert tools, LLM expansion, and DPO-based refinement is robust and yields significant empirical gains.